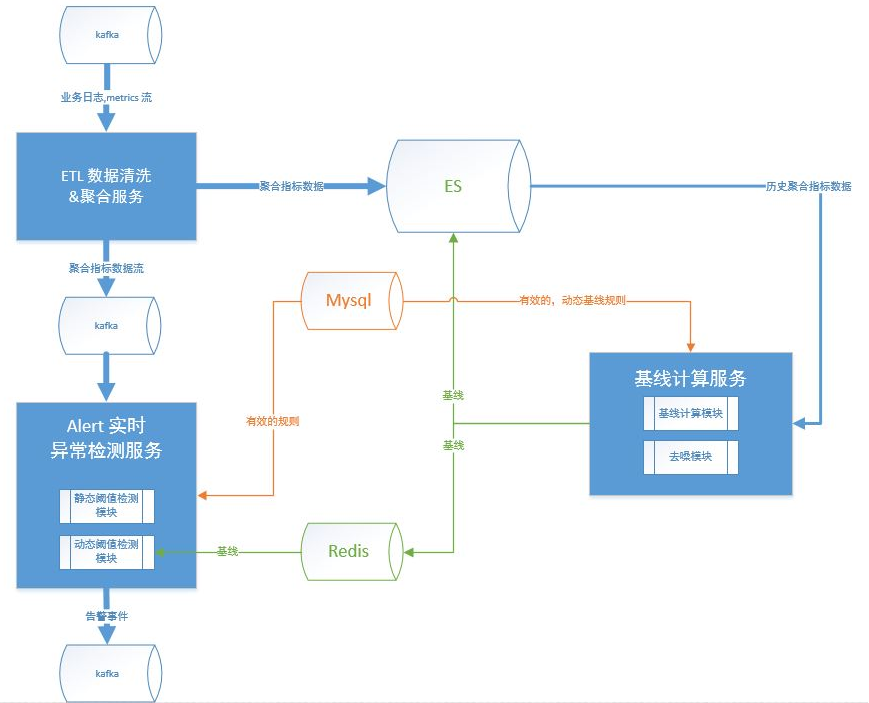
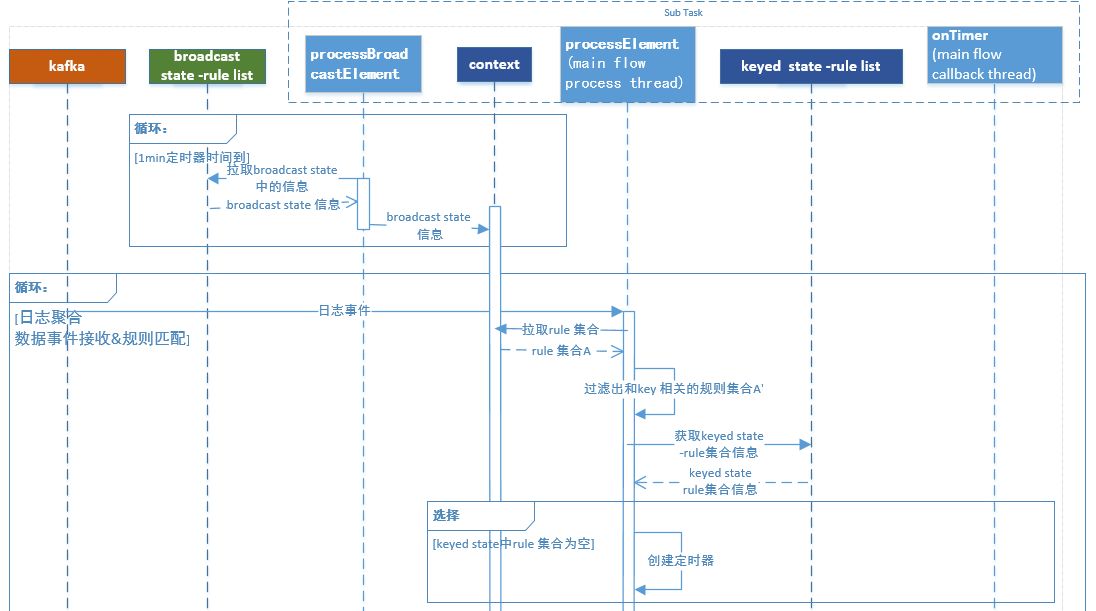
0
无法提供摘要。这是一篇受保护的文章。...
早睡早起


无法提供摘要。这是一篇受保护的文章。...
背景: 用于公有云售卖区云上saas应用的压测场景 功能点: 利用k8s的资源管理能力实现分布式压测和资源的弹性伸缩 支持jmeter 压测引擎 支持性能核心指标(QPS,99%RT,90%RT,成功率,失败数)的实时监控(jmeter引擎) 支持多租户(多个用户共享压测资源池) 模块介绍 Front:用户操作界面:选择压测引擎,编辑压测场景信息,上传�...
无法提供摘要。这是一篇受保护的文章。...
无法提供摘要。这是一篇受保护的文章。...
无法提供摘要。这是一篇受保护的文章。...
无法提供摘要。这是一篇受保护的文章。...
算法复杂度 含义: 衡量算法相对(排除物理机性能的影响)性能的标记方法 Q:为什么插值排序的算法复杂度是 A:多次循环嵌套的操作次数计算公式得到(1+n)*n/2, 取最大的阶数得到 n平方, Theta 符号表示取最高阶 Q: 算法复杂度高的算法什么时候有用? A: 在数据集 数量级比较小的场景还是适用的 Q:为什么归并排序的算法复杂度�...
无法提供摘要。这是一篇受保护的文章。...
无法提供摘要。这是一篇受保护的文章。...
无法提供摘要。这是一篇受保护的文章。...