算法复杂度 含义: 衡量算法相对(排除物理机性能的影响)性能的标记方法
Q:为什么插值排序的算法复杂度是
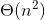
A:多次循环嵌套的操作次数计算公式得到(1+n)*n/2, 取最大的阶数得到 n平方, Theta 符号表示取最高阶
Q: 算法复杂度高的算法什么时候有用?
A: 在数据集 数量级比较小的场景还是适用的
Q:为什么归并排序的算法复杂度是 什么?
归并排序主要使用一个基于2叉树的递归算法:
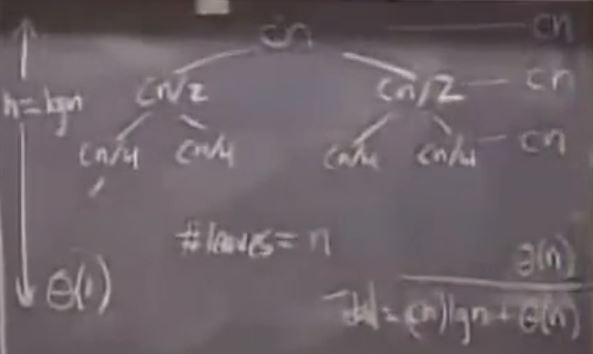
推导:
- 每层叶子节点个数都是 n的常数倍:Cn
- 最后一层叶子节点的个数是:Theta (n)
- 二叉树的高度(层数)为:lgn (以2为底的对数是lg???)
- 所有的计算量为–所有树枝节点*二叉树层数+所有叶子节点的计算量: Cn*lgn+Theta(n)
- 取高阶 为: Theta(n*lgn)
所以归并排序时间复杂度为: Theta (N* logN)
大部分性能优化 的 算法部分优化思路都是把 非hash算法 改成hash 算法(复杂度是Theta (n))
Q: O的含义?欧米噶的含义?
A:O大概表示<=, 算法复杂度上界
欧米噶表示 >=, 算法复杂度 下界
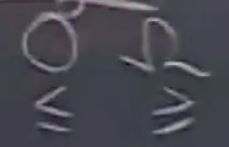
Q: 算法复杂度的链式公式
不能反向推导
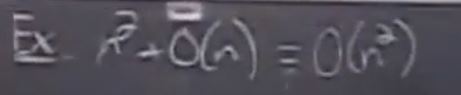
大数据应用中算法时间复杂度对应用实时性影响很大,空间复杂度对资源消耗影响很大(比如flink中state ),理解好常见算法复杂度必不可少
- 字符串操作
以最常见的连续内存 存储 –数组为基础分析
- 增加: 涉及到插入字符串后的部分字符串的挪移操作,所以时间复杂度是O(n)
- 删除: 删除同样涉及字符串的挪移,时间复杂度是O(n)
- 查询:
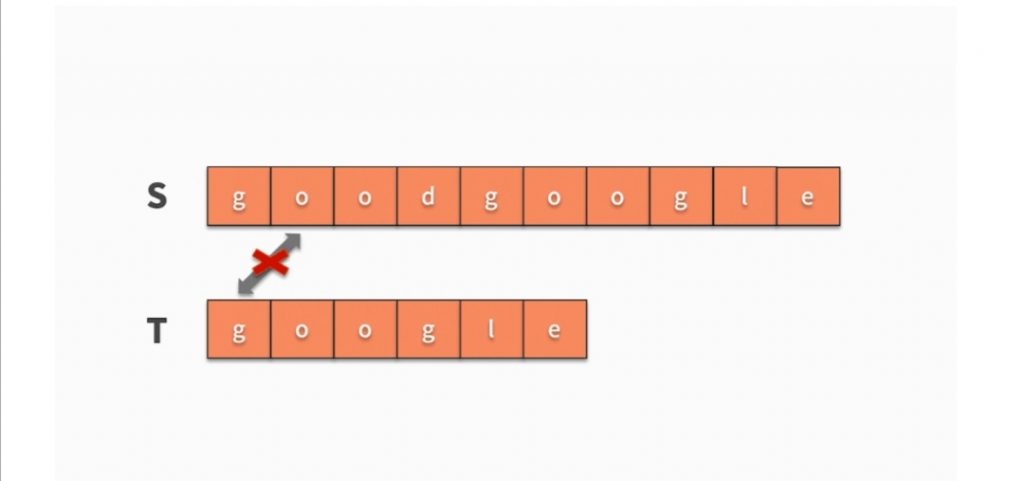
步骤:
- 循环1: 查找字符串S(长度为n),T(长度为m)中第一个字符相等的位置
- 循环2: 基于外层循环查找的相等的位置匹配后续字符是否相等
字串查询的时间复杂度为O(nm)
2. 如何查找2个数组中不同的元素,时间复杂度和空间复杂度最优?
方案1:
for (T t : ListA) {
if (!ListB.contains(t)) {
不相同的集合.add(t);
}
}
其中 :
不相同的集合 为 放不相同元素的集合ListA长度为m , ListB长度为n, 由于ListB.contains()会触发一次O(n)遍历, 因此时间复杂度为O(mn):
方案2 : 一个数组转换为hash , 一个仍然使用数组遍历,但是空间复杂度增加一个hash 表, 时间复杂度为 O(n)+O(n)=O(n)
List<Object> rules1;
Map<Integer, String> resultsMap = new HashMap<Integer, Object>();
for (Object o : rules1) {
rulesMap.put((Integer) o.id, o);
}
List<Object> rules2;
for (Object o : rules2) {
if(rulesMap.get(o.id)==null){
rules2.remove(o);
}
}3. 给定一个按非递减顺序排序的整数数组 A,返回每个数字的平方组成的新数组,要求也按非递减顺序排序。已知输入条件:
1 <= A.length <= 10000
-10000 <= A[i] <= 10000
A 已按非递减顺序排序。
比如: 输入:[-4,-1,0,3,10], 输出:[0,1,9,16,100]
方案1: 先遍历A算出平方,再遍历—– 时间复杂度:O(N log N)
public int[] sortedSquares(int[] A) {
int N = A.length;
int[] ans = new int[N];
for (int i = 0; i < N; ++i)
ans[i] = A[i] * A[i];
Arrays.sort(ans);
return ans;
}
方案2:边遍历计算平方边排序——–时间O(n) 空间O(n)
class Solution {
public int[] sortedSquares(int[] A) {
int length;
if (A == null || (length = A.length) == 0) {
return new int[0];
}
int i = 0;
int j = length - 1;
int k = length - 1;
int[] result = new int[length];
while (i <= j) {
int temp;
if (A[i] * A[i] > A[j] * A[j]) {
temp = A[i] * A[i];
i++;
} else {
temp = A[j] * A[j];
j--;
}
result[k--] = temp;
}
return result;
}
}4. 数组中占比超过一半的元素称之为主要元素。给定一个整数数组,找到它的主要元素。若没有,返回-1。
方案1:遍历数组,并使用hash 计数, 时间复杂度:O(n), 空间复杂度: O(n)
public static int majorityElement(int[] nums) {
Map<Integer, Integer> IntMap=new HashMap<Integer,Integer>();
int len=nums.length/2;
for(int a:nums){
if(null!= IntMap.get(a)) {
IntMap.put(a, IntMap.get(a) + 1);
if (IntMap.get(a) > len) {
return a;
}
}else{
IntMap.put(a,1);
}
}
return -1;
}
3. 二叉查找树
查找数据: O(logn)
插入数据: 查找插入位置(O(logn))+插入操作(O(1))
删除数据: 查找待删除的数据的位置O(logn)+ 删除操作—
- 叶子节点删除:O(1)
- 待删除节点有1个子节点:查找替换该节点的节点位置O(logn),再删除 O(1)
- 待删除节点有2个子节点: 查找替换该节点的位置 O(logn) ,再删除 O(1)
4. Hash 表
- 使用函数实现地址索引
- hash函数设计目标需要减少hash冲突
hash 函数设计要素:
- hash 函数返回值需要是非负值;
- 如果key1==key2, 则f(key1)==f(key2)
- 如果 key1!=key2, 则f(key1)!=f(key2)
没有评论