智能算法系统如何评估?
主要衡量模型对未知新数据的预测能力,即泛化能,衡量泛化能力的指标(也叫模型的性能度量):
1.1 准确率(accuracy) :对于给定的数据集,正确分类的样本数占总样本数的比率。
1.2 精确率(precision)==查准率:对于给定的数据集,预测为正例的样本中真正例样本的比率。
1.3 召回率( recall)==查全率,对于给定的数据集,预测为真正例的样本占所有实际为正例样本的比率
1.4 ROC与AUC —分类算法评价指标 F1值 是精确率和召回率的调和均值
1.5 MSE(均方误差),RMSE(均方根误差),MAE(平均绝对误差)、R-Squared(拟合度) —-回归算法评价指标
1. 测试算法多次运行的结果的稳定性,比如同一个输入,多次执行的输出结果不一样就比较麻烦;
2. 数据输入值发生微小变化时,输出的变化是否很大,如果很大表示算法不是很稳定;
3. 适应性–适应变化的输入和各种数据类型。
对抗性样本 adversarial examples:在数据集中通过故意添加细微的干扰所形成输入样本,受干扰之后的输入导致模型以高置信度给出错误的输出。
4. 数据集分布发生迁移对算法运行的影响;
把算法模型代码作为一个整体,和常规的系统一样测试
1. 场景符合度
满足用户场景的需求
2.计算复杂度,时间成本
响应时间 response time: 在给定的软硬件环境下,深度学习算法对给定的数据进行运算并获得结果所需要的时间。
3. 系统模块监控
和正常系统模块一样,监控资源利用率等
4、可移植性:
软硬件平台依赖对算法运行的影响:
深度学习框架差异, 操作系统差异, 硬件架构差异
和常规的系统模块类似,观察算法模块之间的交互数据是否符合预期;
针对竞争产品做对比测试,参考上述维度做对比优劣, 比如 AI 音箱产品
测试数据
测试人员很大一部分工作就是在准备测试数据,尽量和线上环境保持一致, 比如收集大量的图片, 大量的语料,并且还需要打好标签, 工作量比较大;而且用户量变大后,数据集分布可能会演化,而导致原有算法性能下降,需要定期用新的数据重新训练算法模型,因此测试集的选择非常重要
a. 测试集和训练集的分布一致
比如都包含 美国的X数据,印度的X数据等, 不能是测试集用美国数据,而训练集使用印度数据
b. 测试数据的数量和训练数据数量的比例合理
数据量比较小时,可以是7:3左右,如果是百万级及以上,则是98:2 左右的比例
数据集的质量保证
1.不同的智能产品数据类型不一样,比如像基于协同的商品推荐算法数据大部分是数值类(来自于产品每天产生的大量实时埋点日志),一般会存放在Hadoop这类的大数据平台上,方便做数据挖掘和存储;这类数据的检查基本上都是基于Hadoop/spark之类的计算框架 做数据检查,可以支持的检查脚本比较简单,有类SQL的,也支持Python等脚本的方式; 主要检查点包括: 数据的值是否超出正常范围(比如 电影年代不能<1900之类的),非空检查, 异常枚举值检查等等; 检查任务可以设置定时任务定期扫描相关的表;
2. 智能语音音箱产品, 数据集可能来源是音频转语料,产品没有卖出去之前,并没有太多现成的数据可用, 所以需要很多人工造大量语料,并打标签,然后再倒入数据库管理;当然,产品卖出后是可以收集到很多实际音频和语料(通过工具把音频转成语料)信息的,可以用于后续数据处理和训练,以及测试使用;这一类的数据检查会比较麻烦,没有明确的规则,目前还是通过找众包去审核为主…
 语义识别测试
测试人员大部分时间会花在构造语义测试数据阶段。尽可能的收集各种语境和语义输入。
语义识别测试
测试人员大部分时间会花在构造语义测试数据阶段。尽可能的收集各种语境和语义输入。
- 构造语义测试数据的方法:
发布前
语义测试开展(构造语义测试数据的四个阶段)
人工脑暴数据
实体扩充
模板库 + 实体库自动化生成数据
热门实体库更新(实体库为FM节目、FM专辑、音乐热歌、音乐新歌等)
同音字替代
实体少字
模糊音替代
干扰语气词
重叠字
实体颠倒
实体含英文,数字等
同义词扩充(同义词替代增长测试数据)
https://blog.csdn.net/u014411730/article/details/78625226
3. 图像识别类产品, 数据集可能大部分是来自于网络爬取的图片+ 线上的图片(如果没有权限限制的话),一般网上爬取的图片质量参差不齐,也需要做一些人工的修整,一般有OpenCV等工具可以做图像处理; 还有一些工具可以提供简单的人脸识别,把图像中的人脸扣出来,可以用于人脸识别模型的训练; 总之图像数据的质量还是需要部分人为检查,特别是网上图片,避免出现拉伸或压缩的图片影响训练效果
在线预测服务
在线预测服务就是把线下训练好的模型部署到预发、线上环境供业务系统调用,一般大型服务都需要分布式+集群部署;
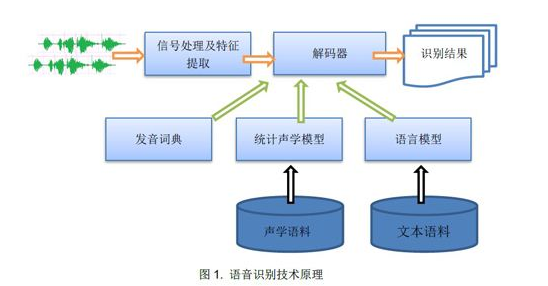
比如语音识别系统, 一般分为接入层,算法层, 数据层; 整个算法层也是由很多层分类算法,RNN算法模块组成,核心算法模块都需要集群部署;一般大型互联网公司提供强大的基础设施服务 和监控,方便弹性扩展保证系统可用性;数据层一般是提供答复用户语料的数据信息, 一般是RPC调用一些业务服务查询数据,比如商品信息, 歌曲信息等等, 有的场景可能调用第三方的服务,需要服务的微服务架构(熔断机制等)保证 每次查询的可用性;
测试工具、平台
一般测试工具一般用于一下功能(以 语音识别算法系统为例):
a.测试数据,预期结果的录入和存储
b. 对接预发,线上环境执行测试(调用接口),比对预期结果,产生统计报表
c. CI 保持持续集成测试能力
d. 对接链路监控模块,方便查询 性能瓶颈
没有评论