1. 问题分析
基于房屋的各种纬度特征,预测房屋价格
2.原始数据扒取
从http://hz.ganji.com/fang5 网站上扒取 杭州市房屋特征数据:
'Address':div.find('span',class_=re.compile('area')).text.strip().replace(' ','').replace('\n',''),
'Rooms': div.find('dd', class_=re.compile('size')).contents[1].text.strip(),#tag的 .contents 属性可以将tag的子节点以列表的方式输出
'Area':div.find('dd',class_=re.compile('size')).contents[5].text.strip(),
'Towards':div.find('dd',class_=re.compile('size')).contents[9].text.strip(),
'Floor':div.find('dd',class_=re.compile('size')).contents[13].text.replace('\n','').strip(),
'Decorate':div.find('dd',class_=re.compile('size')).contents[17].text.strip(),
'Feature':div.find('dd',class_=re.compile('feature')).text.replace('\n','_').strip(),
'TotalPrice':div.find('span',class_=re.compile('js-price')).text.strip()+div.find('span',class_=re.compile('yue')).text.strip(),
'Price':div.find('div',class_=re.compile('time')).text.strip()
代码:https://github.com/margaretmm/pricePrediction/blob/master/clawer.py
3.特征工程
做了很多事情:
(1) 数据清理:填写缺失值,光滑噪声数据等等。
(2) 数据集成:将多个数据源合成同一个数据来源。
(3) 数据变换:平滑聚集,数据概化等等
详细参看详细说明
import numpy as np
import pandas as pd
import re
#对房间个数做数值化处理
def roomChange(x):
if "1室" in x:
return 1
elif "2室" in x:
return 2
elif "3室" in x:
return 3
elif "4室" in x:
return 4
elif "5室" in x:
return 5
elif "6室" in x:
return 6
else:
return 10
#对房间朝向做数值化处理
def TowardChange(x):
if x.contains("南"):
return 1
def Wash(area='bingjiang', index=0):
dfName='Data_'+area+'_g'+str(index)+'.csv'
df = pd.read_csv(dfName, sep=',')
pd.set_option('max_colwidth',100)
pd.set_option('display.max_columns', None)
# if df.empty():
# print("read_csv from " +dfName+" have no data!!!")
# exit(1)
del df['Address']
col=['Address','Rooms', 'Area', 'Towards', 'Floor', 'Decorate','Feature', 'TotalPrice', 'Price']
#填充缺失数据
df=df.fillna(0)
#print(df['Towards'].str.index("南")>-1)
df['Rooms']=df['Rooms'].apply(lambda x: roomChange(x))
# 装修情况数值化处理
df['Decorate']=np.array(df['Decorate'].str.contains("装修").astype(np.int))
#df['Decorate']=[1 if x and "装修" in x else 0 for x in df.Decorate]
#print(df.head(3))
cols = list(df)
cols.insert(2, cols.pop(cols.index('Decorate')))
df = df.ix[:, cols]
# 把一个复合特征的列分解解析出3个新的特征列subway,FiveYear,hasLift
df.insert(3, 'subway', 0)
df.insert(4, 'FiveYear', 0)
df.insert(5, 'hasLift', 0)
#print(df.head(3))
# for x in df.Feature:
# print(x)
# print( "距离" in x)
# subway,FiveYear,hasLift 特征数值化
df['subway']=[1 if x!=0 and "距离" in x else 0 for x in df.Feature]
df['FiveYear']=[1 if x!=0 and "满五" in x else 0 for x in df.Feature]
df['hasLift']=[1 if x!=0 and "电梯" in x else 0 for x in df.Feature]
del df["Feature"]
# 朝向特征数值化
df['Toward_s']=np.array(df['Towards'].str.contains("南")).astype(np.int)
df['Toward_n']=np.array(df['Towards'].str.contains("北")).astype(np.int)
df['Toward_e']=np.array(df['Towards'].str.contains("东")).astype(np.int)
df['Toward_w']=np.array(df['Towards'].str.contains("西")).astype(np.int)
del df['Towards']
# 楼层特征数值化
df['Floor_h']=np.array(df['Floor'].str.contains("高")).astype(np.int)
df['Floor_m']=np.array(df['Floor'].str.contains("中")).astype(np.int)
df['Floor_l']=np.array(df['Floor'].str.contains("低")).astype(np.int)
del df['Floor']
# 购买年限特征数值化
#print(dfName.__contains__("g1"))
if dfName.__contains__("g1"):
df['BuyYesrs<3']=np.array(1).astype(np.int)
df['BuyYesrs_3_5']=np.array(0).astype(np.int)
df['BuyYesrs_6_10']=np.array(0).astype(np.int)
df['BuyYesrs>10']=np.array(0).astype(np.int)
elif dfName.__contains__("g2"):
df['BuyYesrs<3']=np.array(0).astype(np.int)
df['BuyYesrs_3_5']=np.array(1).astype(np.int)
df['BuyYesrs_6_10']=np.array(0).astype(np.int)
df['BuyYesrs>10']=np.array(0).astype(np.int)
elif dfName.__contains__("g3"):
df['BuyYesrs<3']=np.array(0).astype(np.int)
df['BuyYesrs_3_5']=np.array(0).astype(np.int)
df['BuyYesrs_6_10']=np.array(1).astype(np.int)
df['BuyYesrs>10']=np.array(0).astype(np.int)
elif dfName.__contains__("g4"):
df['BuyYesrs<3']=np.array(0).astype(np.int)
df['BuyYesrs_3_5']=np.array(0).astype(np.int)
df['BuyYesrs_6_10']=np.array(0).astype(np.int)
df['BuyYesrs>10']=np.array(1).astype(np.int)
#print(df.head(15))
# for x in df.Price:
# print(x)
# a=re.findall(r"^(\d+)", x)
# print(a[0], type(a))
# 清理数据中非数值的内容
df['Price']=[re.findall(r"^(\d+)", x)[0] if u"元/㎡" in x else 0 for x in df.Price]
df['Price'] = df['Price'].astype(np.float64)
# 数据清理,清理掉异常的Price值的数据
df = df[(df['Price']>5000) &(df['Price']<80000)]
# 清理TotalPrice数据中非数值的内容
df['TotalPrice']=[re.findall(r"^(\d+)", x)[0] if u"万元" in x else 0 for x in df.TotalPrice]
df['TotalPrice'] = df['TotalPrice'].astype(np.float32)
# 数据清理,清理掉异常的TotalPrice值的数据
df = df[(df['TotalPrice']>60) &(df['TotalPrice']<1800)]
# 清理Area数据中非数值的内容
df['Area']=[re.findall(r"^(\d+)", x)[0] if u"㎡" in x else 0 for x in df.Area]
df['Area'] = df['Area'].astype(np.float32)
# 数据清理,去重
df.drop_duplicates()
#新增特征列,判断是否是商品房
df['ProductHouse']=np.array(df['Area']>50).astype(np.int)
#新增特征列,判断房屋的地理区域,并数值化
df['area_bj']=np.array(0).astype(np.int)
df['area_gs']=np.array(0).astype(np.int)
df['area_yh']=np.array(0).astype(np.int)
df['area_xh']=np.array(0).astype(np.int)
df['area_xc']=np.array(0).astype(np.int)
df['area_xs']=np.array(0).astype(np.int)
if dfName.__contains__("binjiang"):
df['area_bj']=np.array(1).astype(np.int)
elif dfName.__contains__("gongshu"):
df['area_gs']=np.array(1).astype(np.int)
elif dfName.__contains__("xihu"):
df['area_xh']=np.array(1).astype(np.int)
elif dfName.__contains__("xiacheng"):
df['area_xc']=np.array(1).astype(np.int)
elif dfName.__contains__("xiaoshan"):
df['area_xs']=np.array(1).astype(np.int)
elif dfName.__contains__("yuhang"):
df['area_yh']=np.array(1).astype(np.int)
df.to_csv('Data_washed_'+dfName.split('_')[1]+dfName.split('_')[2],sep=',',index=None)
if __name__ == '__main__':
#for i in ['binjiang','gongshu','xiacheng','xihu','yuhang','xiaoshan']:
for i in ['binjiang']:
for j in [1,2,3,4]:
print(i)
print(j)
Wash(i,j)
(4) 特征分析
分析价格分布区间,是否有非常异常的数据,生僻数据可以选择删除

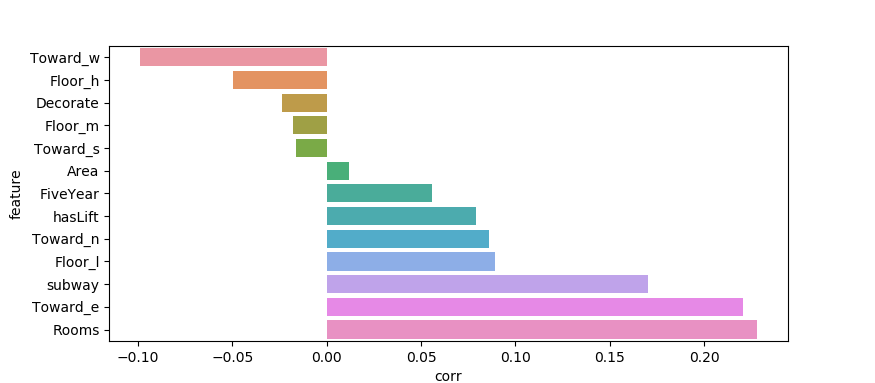
分析各个纬度特征与房价之间的关系,哪些是强特征,哪些是弱相关特征:
下图中房间数,朝东,是否有地铁等特征与 房价是正强相关;
朝西 等特征是强负相关特征;
当然这些统计都是基于扒取的数据,如果觉得不准,可以再看看数据纬度是否可以增加,已有数据是否需要继续清洗;
如果为了防止过拟合,可以选择删除弱相关特征,之后再做模型训练;
4.模型选择&训练
可用的算法有:1. 传统的机器学习算法:随机森林。。。2. 神经网络 NN
本样例基于NN算法介绍一下实现过程:
4.1引入需要的包:
import tensorflow as tf ----提供梯度下降功能 from sklearn.datasets import load_boston ----提供数据导入功能 import matplotlib.pyplot as plt ----提供绘图功能 from sklearn.preprocessing import scale ----提供数据预处理功能,比如 参数标准化 from sklearn.model_selection import train_test_split ----提供数据集拆分功能,按照一定比例拆分成训练、测试集 import pandas as pd -----提供数据编辑功能,主要是dataframe结构
4.2 加载数据&数据预处理:
boston = load_boston() # 参数标准化,为了提升梯度下降的速度 X = scale(boston.data) y = scale(boston.target.reshape((-1,1))) #标准化后再做一次矩阵变换 # 在一个大数据集中按照1:9的比例划分测试集,训练集 len=boston.data.shape[1] X_train,X_test,y_train,y_test = train_test_split(boston.data,boston.target,test_size=0.1,random_state=0)
这个是我个人的数据集
#数据加载 dfTrain='Data_washed_all2.csv' keep_prob=1 df = pd.read_csv(dfTrain,header=0) #使用Dataframe结构从数据集中提取 Y列和X列集合 arr=["Rooms","Area","Decorate","subway","FiveYear","Toward_s","Toward_e","Toward_w","Floor_h","Floor_m","Floor_l","BuyYesrs<3","BuyYesrs_3_5","BuyYesrs_6_10","BuyYesrs>10","ProductHouse","area_bj","area_gs","area_yh","area_xh","area_xc","area_xs"] len=len(arr) df_train=df[arr].values df_target=df["Price"].values # 数据集按照比例拆分 X_train,X_test,y_train,y_test = train_test_split(df_train,df_target,test_size=0.1,random_state=0) #对每个数据集做标准化操作,为了后续梯度下降性能考虑 X_train = scale(X_train) X_test = scale(X_test) y_train = scale(y_train.reshape((-1,1))) y_test = scale(y_test.reshape((-1,1)))
4.3. 构建NN网络结构
# batch X ,Y矩阵准备–使用占位符placeholder保留行数为未知值,后续执行时再填入每次的Batch值
xs = tf.placeholder(shape=[None,X_train.shape[1]],dtype=tf.float32,name="inputs") ys = tf.placeholder(shape=[None,1],dtype=tf.float32,name="y_true") keep_prob_s = tf.placeholder(dtype=tf.float32)
# 构建各层NN网络,第一层为多参数线性回归函数+Relu激活函数(还有DropOut层防止过拟合),第二层为线性回归函数层(无激活函数)
with tf.name_scope("layer_1"):
l1 = add_layer(xs,len,10,activation_function=tf.nn.relu)
with tf.name_scope("y_pred"):
pred = add_layer(l1,10,1)
# 这里多于的操作,是为了保存pred的操作,做恢复用。我只知道这个笨方法。 pred = tf.add(pred,0,name='pred')
def add_layer(inputs,input_size,output_size,activation_function=None):
with tf.variable_scope("Weights"):
Weights = tf.Variable(tf.random_normal(shape= [input_size,output_size]),name="weights")
with tf.variable_scope("biases"):
biases = tf.Variable(tf.zeros(shape=[1,output_size]) + 0.1,name="biases")
with tf.name_scope("Wx_plus_b"):
Wx_plus_b = tf.matmul(inputs,Weights) + biases
with tf.name_scope("dropout"):
Wx_plus_b = tf.nn.dropout(Wx_plus_b,keep_prob=keep_prob_s)
if activation_function is None:
return Wx_plus_b
else:
with tf.name_scope("activation_function"):
return activation_function(Wx_plus_b)
4.4 定义梯度下降函数
# 这里使用指数衰减的学习率,定义相关参数
initial_learning_rate = 0.001
global_step = tf.Variable(0, trainable=False)
decay_steps = 200
decay_rate = 0.98
#定义Loss函数
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - pred),reduction_indices=[1])) # mse
tf.summary.scalar("loss",tensor=loss)
#定义学习率为指数衰减形式
with tf.name_scope("train"):
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step, decay_steps, decay_rate, True,name='learning_rate')
# Passing global_step to minimize() will increment it at each step.
#定义梯度下降函数
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss,global_step = global_step)
4.5 Minibatch 执行NN网络
def fit(X, y, ax, n, keep_prob):
#定义 初始化函数
init = tf.global_variables_initializer()
# 填充展位符
feed_dict_train = {ys: y, xs: X, keep_prob_s: keep_prob}
#开始运行TF Session执行之前定义的TF函数
with tf.Session() as sess:
#写tensorbord
saver = tf.train.Saver(tf.global_variables(), max_to_keep=15)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter(logdir="nn_boston_log", graph=sess.graph) #执行初始化函数(分配资源)
sess.run(init)
#按批次执行TF 之前定义的Loss函数,和梯度下降函数,并定期打印epoch轮次和Loss函数结果值
for i in range(n):
_loss, _ = sess.run([loss, train_op], feed_dict=feed_dict_train)
if i % 100 == 0:
print(sess.run([learning_rate]))
print("epoch:%d\tloss:%.5f" % (i, _loss))
y_pred = sess.run(pred, feed_dict=feed_dict_train)
rs = sess.run(merged, feed_dict=feed_dict_train)
#写tensorbord
writer.add_summary(summary=rs, global_step=i)
# 保存模型
saver.save(sess=sess, save_path="nn_boston_model/nn_boston.model", global_step=i)
#图像展示
try:
ax.lines.remove(lines[0])
except:
pass
lines = ax.plot(range(50), y_pred[0:50], 'r--')
plt.pause(1)
# 保存模型
saver.save(sess=sess, save_path="nn_boston_model/nn_boston.model", global_step=n) # 保存模型
—————————————————————————————–
# 执行Fit函数—执行Session入口
keep_prob=0.8 # 防止过拟合,取值一般在0.5到0.8 ITER =30000 # 训练次数 fit(X=X_train,y=y_train,n=ITER,keep_prob=keep_prob,ax=ax)
使用这个NN,对网上数据和我个人的数据都试用了一下
网络数据训练效果比较好loss在0.3, 而个人数据loss在0.6就无法下降了,
尝试了很多方法:
- 增加数据集(没有效果)
- 调整学习率, 把学习率从定值改为指数衰减(效果甚微)
- 增加一层relu层(负效果)
- 数据集增加 一个纬度特征(有一定效果,loss稍微降了0.1)
结论: 优化预测精准度,需要数据增加更多的更有效的特征值
没有评论
评论已关闭。