1. 问题分析
发布一个子系统到线上,根据测试流程中收集的质量数据 预测其可能的 线上问题数;
2. 模型设计
一般影响子系统质量的因素可能有哪些? 能获取到多少纬度的数据,取决于各厂的质量大数据平台的数据挖掘能力,
这里,由于本人无实际数据平台,举个样例,纬度不一定齐全

构造的训练数据: https://github.com/margaretmm/AI/blob/master/data_train_2.csv
构造的测试数据: https://github.com/margaretmm/AI/blob/master/data_test_2.csv
3. 特征工程
目的:
a. 为了在选择模型前,理解特征相关性,为了防止过拟合, 可以只筛选一些强相关性的特征做模型训练;(当然,如果使用NN模型,可以不用考虑这一点)
分析历史线上问题的分布情况:
count 29.000000
mean 0.448276
std 0.572351
min 0.000000
25% 0.000000
50% 0.000000
75% 1.000000
max 2.000000
各特征对 预期值的影响强弱关系: 系统复杂度对线上问题个数影响是最大的(至少我潜意识是这么认为的…所以数据构造就成这样了…),代码修改量影响最小;
如果特征很多的情况下,可以考虑把弱相关特征剔除,但我这里没有做剔除,因为纬度也不是很多;

特征分析代码:https://github.com/margaretmm/AI/blob/master/featureAnalize.py
b. 识别无效特征,比如缺失值和存在真实值的样本比例比较大的特征
c. 连续变量缺失值补全
我的数据都是自己构造的,暂时不存在这2种问题
d. 特征数值化
上述模型大部分是数值属性, 只有系统新增功能复杂度,属性需要数值化处理一下:
由于对于复杂度的定义的值不一定是线性关系,所以分解成4列分别表示:很复杂(complex_level4),较复杂(complex_level3),一般(complex_level2),简单(complex_level1)这4个属性;
包括其他几个属性的数据如下图:

4. 模型选择&训练
因为数据量不多, 特征纬度也有限,用传统的机器模型即可,比如 随机森林,决策树等,从中选出比较适应数据场景的算法;对新样本的预测也可能是综合多种算法的结果;这里我同时使用了决策树和随机森林 2种算法进行数据分类;
模型代码:https://github.com/margaretmm/AI/blob/master/preditcor_RandomForest_2.py
5. 模型效果:
随机森林 模型参数大部分使用默认参数, 为了提升准确度,可以设置参数n_estimators
n_estimators=1000 #表示随机森林由1000颗决策树组成, 一般决策树多一点,准确率会更高一些
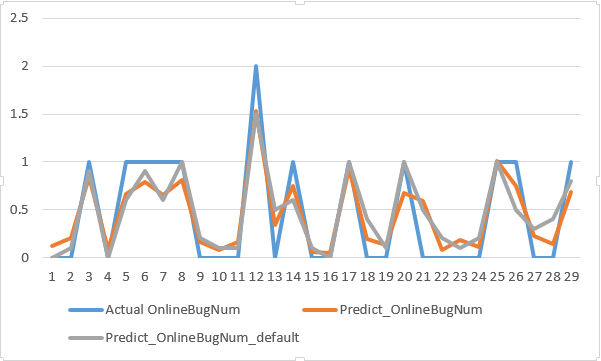
随机森林n_estimators=1000的预测效果: Actual OnlineBugNum,Predict_OnlineBugNum,loss 0,0.119,0.119 0,0.198,0.198 1,0.854,-0.14600000000000002 0,0.091,0.091 1,0.692,-0.30800000000000005 1,0.8,-0.19999999999999996 1,0.659,-0.34099999999999997 1,0.802,-0.19799999999999995 0,0.16,0.16 0,0.061,0.061 0,0.145,0.145 2,1.522,-0.478 0,0.352,0.352 1,0.749,-0.251 0,0.077,0.077 0,0.058,0.058 1,0.935,-0.06499999999999995 0,0.182,0.182 0,0.124,0.124 1,0.657,-0.34299999999999997 0,0.563,0.563 0,0.08,0.08 0,0.178,0.178 0,0.116,0.116 1,1.028,0.028000000000000025 1,0.758,-0.242 0,0.218,0.218 0,0.172,0.172 1,0.681,-0.31899999999999995
随机森林n_estimators 使用默认值的预测效果:
Actual OnlineBugNum,Predict_OnlineBugNum,loss 0,0.2,0.2 0,0.1,0.1 1,0.9,-0.09999999999999998 0,0.1,0.1 1,0.6,-0.4 1,0.9,-0.09999999999999998 1,1.0,0.0 1,1.0,0.0 0,0.3,0.3 0,0.0,0.0 0,0.3,0.3 2,1.7,-0.30000000000000004 0,0.3,0.3 1,0.6,-0.4 0,0.0,0.0 0,0.1,0.1 1,0.9,-0.09999999999999998 0,0.0,0.0 0,0.0,0.0 1,0.5,-0.5 0,0.3,0.3 0,0.1,0.1 0,0.2,0.2 0,0.1,0.1 1,1.0,0.0 1,0.7,-0.30000000000000004 0,0.3,0.3 0,0.2,0.2 1,0.6,-0.4
可视化对比:
predict_OnlineBugNum_default 表示使用默认参数的随机森林模型预测结果
predict_OnlineBugNum表示n_estimators=1000的随机森林模型预测结果,可能数据量不够,精准度稍微弱于默认参数的情况
Actual OnlineBugNum表示实际的测试数据情况
没有评论