一般一个项目质量活动中,性能测试经常发现一些RT时间过长问题和DB服务有关,通常慢查询类问题比较多, 一般影响查询时间长短的主要是对DB索引的理解和使用问题,比如没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷),当然也有一些其他类型的原因,比如查询出的数据量过大(可以采用多次查询或其他的方法降低数据量),锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)sp_lock,sp_who,活动的用户查看,原因是读写竞争资源,还可能是DB所在机器内存,网络资源不够了等等因素导致DB性能不达标;
本文重点针对慢查询没有有效利用索引的场景做简单的原理分析;下面以Mysql为例子,理解一下数据库索引的原理;MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。为了避免混乱,本文将只关注于BTree索引;
1. Mysql索引所采用的数据结构B+Tree及其性能
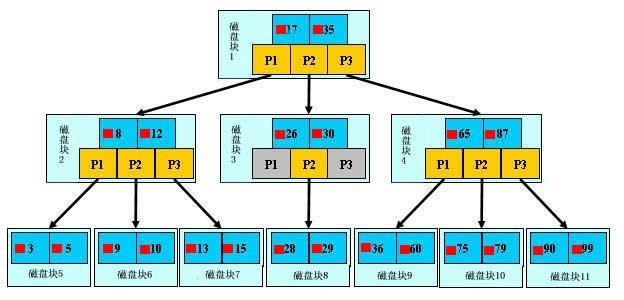
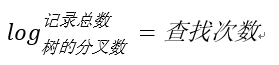
用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用B树类索引会使数据库查询有惊人的性能提升;
B树的搜索复杂度为O(h)=O(logdN),所以树的出度d(一个节点的分叉数)越大,深度h就越小,I/O的次数就越少;3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO…
2. MySQL索引实现
Mysql 主要有MyISAM和InnoDB两个存储引擎的索引实现方式;
2.1 MyISAM索引(非聚集索引)实现
MyISAM引擎使用B+Tree作为索引结构,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。 MyISAM的索引方式也叫做“非聚集”的(索引文件和数据文件是分离的,索引文件仅保存数据记录的地址)。
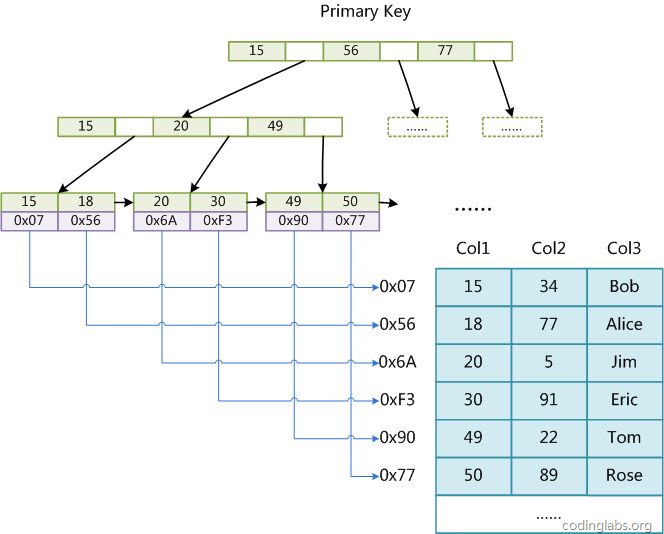
2.2 InnoDB索引(聚集索引)实现
InnoDB也使用B+Tree作为索引结构, 数据文件本身就是索引文件,数据没有单独存储,叶节点包含了完整的数据记录。这种索引叫做聚集索引。
因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
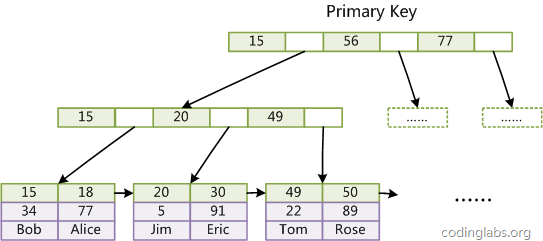
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域(是InnoDB的辅助索引data域存储相应记录主键的值(每个辅助索引的叶子节点只保存主键的值,不会保存一份和主键一样的数据内容,这样会占用大量存储空间)。换句话说,InnoDB的所有辅助索引都引用主键作为data域。这样很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
例如,下图为定义在 人名上的一个辅助索引:
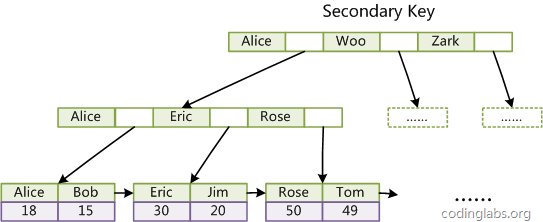
用非单调的字段作为主键在InnoDB中不合适,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键就不会有这种问题。
3. 索引使用策略及优化
3.1 联合索引及最左前缀原理
- 联合索引(复合索引)
相对于一般索引只有一个字段,联合索引可以为多个字段创建一个索引。
它的原理也很简单,比如,我们在(a,b,c)字段上创建一个联合索引,则索引记录会首先按照A字段排序,然后再按照B字段排序然后再是C字段
因此,联合索引的特点就是:
- 第一个字段一定是有序的
- 当第一个字段值相等的时候,第二个字段又是有序的,比如下表中当A=2时所有B的值是有序排列的,依次类推,当同一个B值得所有C字段是有序排列的| A | B | C |
| 1 | 2 | 3 |
| 1 | 4 | 2 |
| 1 | 1 | 4 |
| 2 | 3 | 5 |
| 2 | 4 | 4 |
| 2 | 4 | 6 |
| 2 | 5 | 5 |
其实联合索引的查找就跟查字典是一样的,先根据第一个字母查,然后再根据第二个字母查,或者只根据第一个字母查,但是不能跳过第一个字母从第二个字母开始查。这就是所谓的最左前缀原理。
- 最左前缀原理
还是上面例子,我们在(a,b,c)字段上建了一个联合索引,所以这个索引是先按a 再按b 再按c进行排列的,所以:
以下的查询方式都可以用到索引
select * from table where a=1;
select * from table where a=1 and b=2;
select * from table where a=1 and b=2 and c=3;
上面三个查询按照 (a ), (a,b ),(a,b,c )的顺序都可以利用到索引,这就是最左前缀匹配。
如果查询语句是:
select * from table where a=1 and c=3; 那么只会用到索引a。
如果查询语句是:
select * from table where b=2 and c=3; 因为没有用到最左前缀a,所以这个查询是用户到索引的。
比如:
select * from table where b=2 and a=1;
select * from table where b=2 and a=1 and c=3;
如果用到了最左前缀而只是颠倒了顺序,也是可以用到索引的,因为mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。但我们还是最好按照索引顺序来查询,这样查询优化器就不用重新编译了。
- 前缀索引
前缀索引就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。
前缀索引使用场景:
- 字符串列(varchar,char,text等),需要进行全字段匹配或者前匹配。也就是=‘xxx’ 或者 like ‘xxx%’
- 字符串本身可能比较长,而且前几个字符就开始不相同。比如我们对中国人的姓名使用前缀索引就没啥意义,因为中国人名字都很短,另外对收件地址使用前缀索引也不是很实用,因为一方面收件地址一般都是以XX省开头,也就是说前几个字符都是差不多的,而且收件地址进行检索一般都是like ’%xxx%’,不会用到前匹配。相反对外国人的姓名可以使用前缀索引,因为其字符较长,而且前几个字符的选择性比较高。同样电子邮件也是一个可以使用前缀索引的字段。
- 前一半字符的索引选择性就已经接近于全字段的索引选择性。如果整个字段的长度为20,索引选择性为0.9,而我们对前10个字符建立前缀索引其选择性也只有0.5,那么我们需要继续加大前缀字符的长度,但是这个时候前缀索引的优势已经不明显,没有太大的建前缀索引的必要了。
MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度。但是前缀索引也有它的坏处:MySQL 不能在 ORDER BY 或 GROUP BY 中使用前缀索引,也不能把它们用作覆盖索引(Covering Index)。
3.2 索引优化策略
- 最左前缀匹配原则
- 主键外检一定要建索引
- 对 where,on,group by,order by 中出现的列使用索引
- 尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0
- 对较小的数据列使用索引,这样会使索引文件更小,同时内存中也可以装载更多的索引键
- 索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
- 为较长的字符串使用前缀索引
- 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
- 不要过多创建索引, 权衡索引个数与DML之间关系,DML也就是插入、删除数据操作。这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也需要进行调整重建
- 对于like查询,”%”不要放在前面。
SELECT * FROMhoudunwangWHEREunameLIKE'后盾%' -- 走索引SELECT * FROMhoudunwangWHEREunameLIKE "%后盾%" -- 不走索引 - 查询where条件数据类型不匹配也无法使用索引
字符串与数字比较不使用索引;CREATE TABLEa(achar(10));EXPLAIN SELECT * FROMaWHEREa="1"– 走索引EXPLAIN SELECT * FROM
aWHEREa=1 – 不走索引正则表达式不使用索引,这应该很好理解,所以为什么在SQL中很难看到regexp关键字的原因
没有评论