项目介绍:信用卡欺诈检测—imbalanced-datasets
欺诈行为是小概率事件,因此数据集中欺诈标签的数据比例会比较少,本案例主要介绍标签分布不均衡场景下的数据建模
处于隐私考虑,下面部分数据特征的名字和含义没有,但不影响数据分析;
Time:Number of seconds elapsed between this transaction and the first transaction in the dataset
V1:may be result of a PCA Dimensionality reduction to protect user identities and sensitive features(v1-v28)
V2
V3
V4
V5
V6
V7
V8
V9
V10
V11
V12
V13
V14
V15
V16
V17
V18
V19
V20
V21
V22
V23
V24
V25
V26
V27
V28:abc
Amount:Transaction amount
Class1: for fraudulent transactions, 0 otherwise数据样例:
"Time","V1","V2","V3","V4","V5","V6","V7","V8","V9","V10","V11","V12","V13","V14","V15","V16","V17","V18","V19","V20","V21","V22","V23","V24","V25","V26","V27","V28","Amount","Class"
0,-1.3598071336738,-0.0727811733098497,2.53634673796914,1.37815522427443,-0.338320769942518,0.462387777762292,0.239598554061257,0.0986979012610507,0.363786969611213,0.0907941719789316,-0.551599533260813,-0.617800855762348,-0.991389847235408,-0.311169353699879,1.46817697209427,-0.470400525259478,0.207971241929242,0.0257905801985591,0.403992960255733,0.251412098239705,-0.018306777944153,0.277837575558899,-0.110473910188767,0.0669280749146731,0.128539358273528,-0.189114843888824,0.133558376740387,-0.0210530534538215,149.62,"0"
0,1.19185711131486,0.26615071205963,0.16648011335321,0.448154078460911,0.0600176492822243,-0.0823608088155687,-0.0788029833323113,0.0851016549148104,-0.255425128109186,-0.166974414004614,1.61272666105479,1.06523531137287,0.48909501589608,-0.143772296441519,0.635558093258208,0.463917041022171,-0.114804663102346,-0.183361270123994,-0.145783041325259,-0.0690831352230203,-0.225775248033138,-0.638671952771851,0.101288021253234,-0.339846475529127,0.167170404418143,0.125894532368176,-0.00898309914322813,0.0147241691924927,2.69,"0"
1,-1.35835406159823,-1.34016307473609,1.77320934263119,0.379779593034328,-0.503198133318193,1.80049938079263,0.791460956450422,0.247675786588991,-1.51465432260583,0.207642865216696,0.624501459424895,0.066083685268831,0.717292731410831,-0.165945922763554,2.34586494901581,-2.89008319444231,1.10996937869599,-0.121359313195888,-2.26185709530414,0.524979725224404,0.247998153469754,0.771679401917229,0.909412262347719,-0.689280956490685,-0.327641833735251,-0.139096571514147,-0.0553527940384261,-0.0597518405929204,378.66,"0"
1,-0.966271711572087,-0.185226008082898,1.79299333957872,-0.863291275036453,-0.0103088796030823,1.24720316752486,0.23760893977178,0.377435874652262,-1.38702406270197,-0.0549519224713749,-0.226487263835401,0.178228225877303,0.507756869957169,-0.28792374549456,-0.631418117709045,-1.0596472454325,-0.684092786345479,1.96577500349538,-1.2326219700892,-0.208037781160366,-0.108300452035545,0.00527359678253453,-0.190320518742841,-1.17557533186321,0.647376034602038,-0.221928844458407,0.0627228487293033,0.0614576285006353,123.5,"0"
数据探索:
数值型特征分布:
a. 标签class的分布非常不均衡,值为1的比例不到1%,这样训练的模型容易出现1个问题–过拟合: 使用现有比例的数据,容易让模型认为大部分情况下都是无欺诈行为的,即使模型不能发掘各特征与class的相关性,只要结果是大部分都是0的结果,也会有比较高的准确率
因此需要对模型训练数据集做resample,保证class=0,1的比例为1:1,这样模型的学习效果才会好
b. Time,amount作为特征数据与其他特征数据的单位差距较大,需要做归一化处理
Time V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15 V16 V17 V18 V19 V20 V21 V22 V23 V24 V25 V26 V27 V28 Amount Class
count 284807.000000 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 2.848070e+05 284807.000000 284807.000000
mean 94813.859575 1.165980e-15 3.416908e-16 -1.373150e-15 2.086869e-15 9.604066e-16 1.490107e-15 -5.556467e-16 1.177556e-16 -2.406455e-15 2.239751e-15 1.673327e-15 -1.254995e-15 8.176030e-16 1.206296e-15 4.913003e-15 1.437666e-15 -3.800113e-16 9.572133e-16 1.039817e-15 6.406703e-16 1.656562e-16 -3.444850e-16 2.578648e-16 4.471968e-15 5.340915e-16 1.687098e-15 -3.666453e-16 -1.220404e-16 88.349619 0.001727
std 47488.145955 1.958696e+00 1.651309e+00 1.516255e+00 1.415869e+00 1.380247e+00 1.332271e+00 1.237094e+00 1.194353e+00 1.098632e+00 1.088850e+00 1.020713e+00 9.992014e-01 9.952742e-01 9.585956e-01 9.153160e-01 8.762529e-01 8.493371e-01 8.381762e-01 8.140405e-01 7.709250e-01 7.345240e-01 7.257016e-01 6.244603e-01 6.056471e-01 5.212781e-01 4.822270e-01 4.036325e-01 3.300833e-01 250.120109 0.041527
min 0.000000 -5.640751e+01 -7.271573e+01 -4.832559e+01 -5.683171e+00 -1.137433e+02 -2.616051e+01 -4.355724e+01 -7.321672e+01 -1.343407e+01 -2.458826e+01 -4.797473e+00 -1.868371e+01 -5.791881e+00 -1.921433e+01 -4.498945e+00 -1.412985e+01 -2.516280e+01 -9.498746e+00 -7.213527e+00 -5.449772e+01 -3.483038e+01 -1.093314e+01 -4.480774e+01 -2.836627e+00 -1.029540e+01 -2.604551e+00 -2.256568e+01 -1.543008e+01 0.000000 0.000000
25% 54201.500000 -9.203734e-01 -5.985499e-01 -8.903648e-01 -8.486401e-01 -6.915971e-01 -7.682956e-01 -5.540759e-01 -2.086297e-01 -6.430976e-01 -5.354257e-01 -7.624942e-01 -4.055715e-01 -6.485393e-01 -4.255740e-01 -5.828843e-01 -4.680368e-01 -4.837483e-01 -4.988498e-01 -4.562989e-01 -2.117214e-01 -2.283949e-01 -5.423504e-01 -1.618463e-01 -3.545861e-01 -3.171451e-01 -3.269839e-01 -7.083953e-02 -5.295979e-02 5.600000 0.000000
50% 84692.000000 1.810880e-02 6.548556e-02 1.798463e-01 -1.984653e-02 -5.433583e-02 -2.741871e-01 4.010308e-02 2.235804e-02 -5.142873e-02 -9.291738e-02 -3.275735e-02 1.400326e-01 -1.356806e-02 5.060132e-02 4.807155e-02 6.641332e-02 -6.567575e-02 -3.636312e-03 3.734823e-03 -6.248109e-02 -2.945017e-02 6.781943e-03 -1.119293e-02 4.097606e-02 1.659350e-02 -5.213911e-02 1.342146e-03 1.124383e-02 22.000000 0.000000
75% 139320.500000 1.315642e+00 8.037239e-01 1.027196e+00 7.433413e-01 6.119264e-01 3.985649e-01 5.704361e-01 3.273459e-01 5.971390e-01 4.539234e-01 7.395934e-01 6.182380e-01 6.625050e-01 4.931498e-01 6.488208e-01 5.232963e-01 3.996750e-01 5.008067e-01 4.589494e-01 1.330408e-01 1.863772e-01 5.285536e-01 1.476421e-01 4.395266e-01 3.507156e-01 2.409522e-01 9.104512e-02 7.827995e-02 77.165000 0.000000
max 172792.000000 2.454930e+00 2.205773e+01 9.382558e+00 1.687534e+01 3.480167e+01 7.330163e+01 1.205895e+02 2.000721e+01 1.559499e+01 2.374514e+01 1.201891e+01 7.848392e+00 7.126883e+00 1.052677e+01 8.877742e+00 1.731511e+01 9.253526e+00 5.041069e+00 5.591971e+00 3.942090e+01 2.720284e+01 1.050309e+01 2.252841e+01 4.584549e+00 7.519589e+00 3.517346e+00 3.161220e+01 3.384781e+01 25691.160000 1.000000
非数值型特(暂时不涉及):
数据类型与空值情况:
Data columns (total 31 columns):
Time 284807 non-null float64
V1 284807 non-null float64
V2 284807 non-null float64
V3 284807 non-null float64
V4 284807 non-null float64
V5 284807 non-null float64
V6 284807 non-null float64
V7 284807 non-null float64
V8 284807 non-null float64
V9 284807 non-null float64
V10 284807 non-null float64
V11 284807 non-null float64
V12 284807 non-null float64
V13 284807 non-null float64
V14 284807 non-null float64
V15 284807 non-null float64
V16 284807 non-null float64
V17 284807 non-null float64
V18 284807 non-null float64
V19 284807 non-null float64
V20 284807 non-null float64
V21 284807 non-null float64
V22 284807 non-null float64
V23 284807 non-null float64
V24 284807 non-null float64
V25 284807 non-null float64
V26 284807 non-null float64
V27 284807 non-null float64
V28 284807 non-null float64
Amount 284807 non-null float64
Class 284807 non-null int64数值类特征相关性:
标签很明确就是class, 由于数据分布不均衡,这个原始数据集的相关性矩阵,参考意义不大
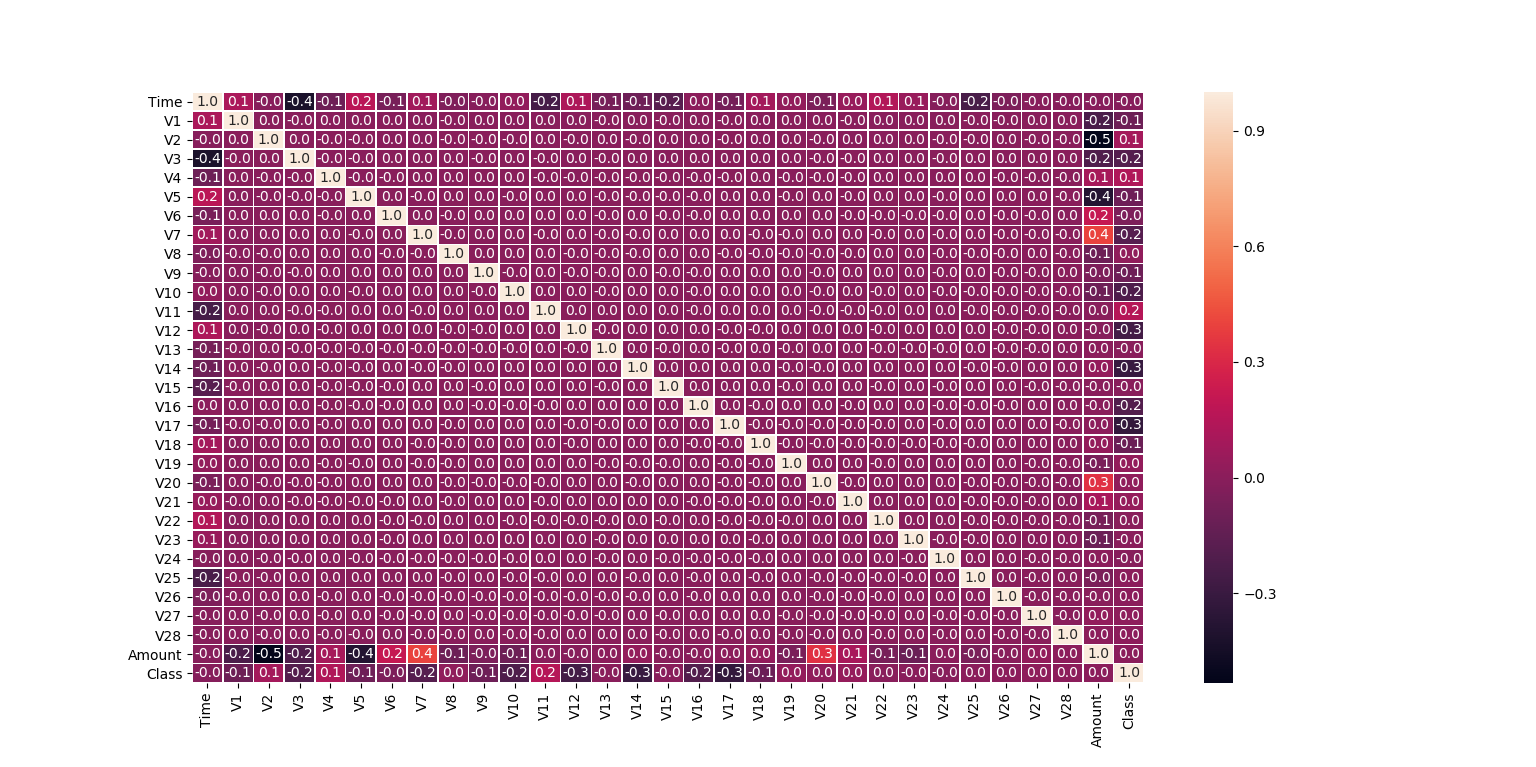
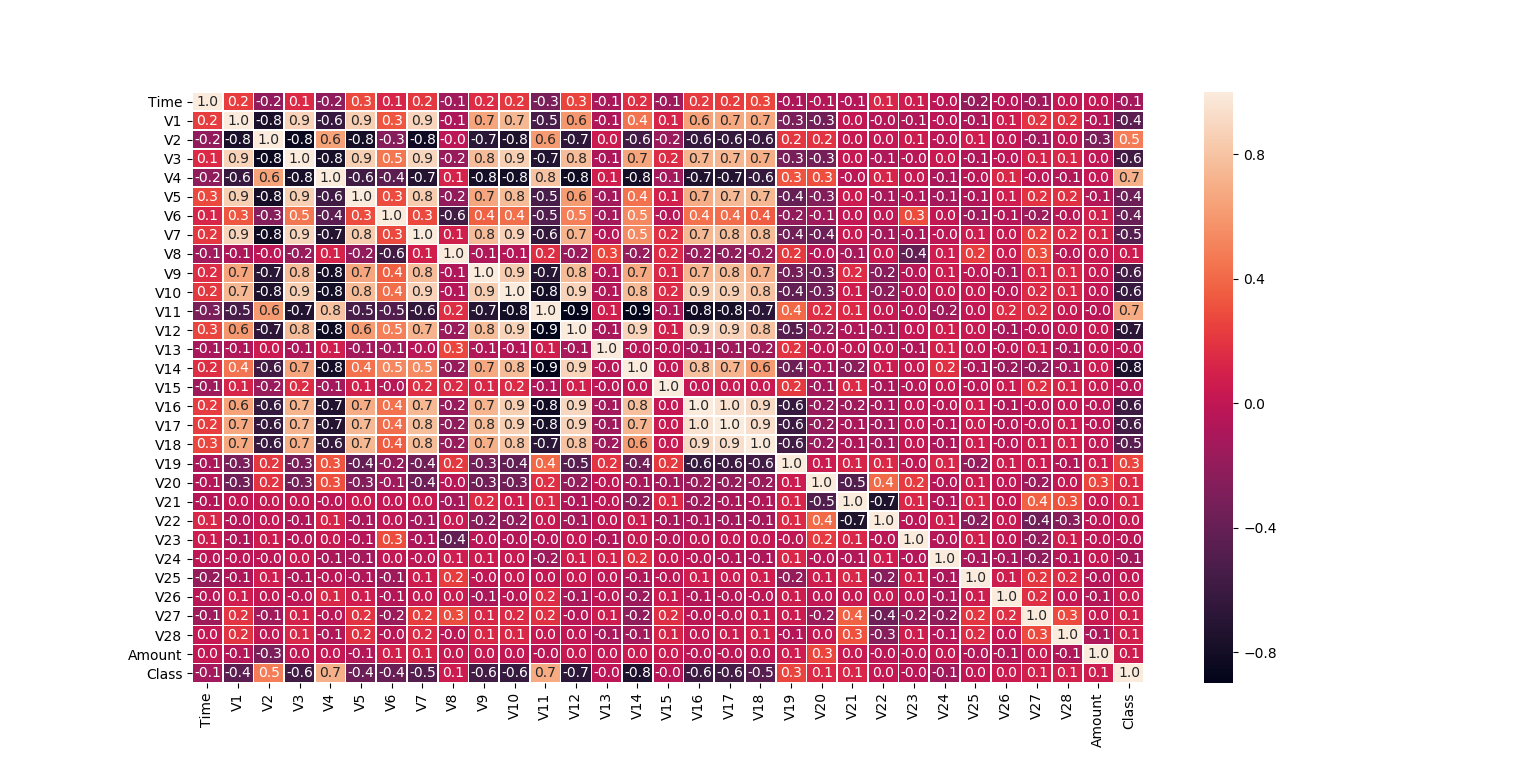
重新resample 使fraud 和非fraud 数据比例为1:1时,再次观察相关性:
df = df.sample(frac=1)
fraud_df = df.loc[df['Class'] == 1]
non_fraud_df = df.loc[df['Class'] == 0][:492]
normal_distributed_df = pd.concat([fraud_df, non_fraud_df])
# Shuffle dataframe rows
new_df = normal_distributed_df.sample(frac=1, random_state=42)
new_df.head()
print('Distribution of the Classes in the subsample dataset')
print(new_df['Class'].value_counts()/len(new_df))
f,ax = plt.subplots(figsize=(10, 10))
sns.heatmap(new_df.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax)
plt.show()resample后数据集中class值的比例:
Distribution of the Classes in the subsample dataset
1 0.5
0 0.5
Name: Class, dtype: float64可以看到特征相关性明显好很多:
可以看到V16,17强相关联,可以做空值相关性预测,或者只保留其中一个特征;
V1 , 3,5,7 之间也是强关联,同上;
…
非数值类特征相关性:(不涉及)
数据实时处理:
flink实时处理需要实现功能:
- 空值,异常值(离均值非常远的值)处理
- 部分特征列的归一化处理
- 分别保存欺诈结果数据和 非欺诈结果数据,方便spark模型训练前统计个数做resample
数据结构类定义:
public class DataCredit implements Serializable {
public Double Time;
public Double TimeScaler;
public Double V1;
public Double V2;
public Double V3;
public Double V4;
public Double V5;
public Double V6;
public Double V7;
public Double V8;
public Double V9;
public Double V10;
public Double V11;
public Double V12;
public Double V13;
public Double V14;
public Double V15;
public Double V16;
public Double V17;
public Double V18;
public Double V19;
public Double V20;
public Double V21;
public Double V22;
public Double V23;
public Double V24;
public Double V25;
public Double V26;
public Double V27;
public Double V28;
public Double Amount;
public Double AmountScaler;
public Double Class;
public DateTime eventTime;
public DataCredit() {
this.eventTime = new DateTime();
}
public void TimeScalerParse(){
this.TimeScaler= dataPrepare.Normalization(this.Time,172792.0, Double.valueOf(0));
}
public void AmountParse(){
this.AmountScaler= dataPrepare.Normalization(this.Amount,25691.16, Double.valueOf(0));
}
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(TimeScaler).append(",");
sb.append(V1).append(",");
sb.append(V2).append(",");
sb.append(V3).append(",");
sb.append(V4).append(",");
sb.append(V5).append(",");
sb.append(V6).append(",");
sb.append(V7).append(",");
sb.append(V8).append(",");
sb.append(V9).append(",");
sb.append(V10).append(",");
sb.append(V11).append(",");
sb.append(V12).append(",");
sb.append(V13).append(",");
sb.append(V14).append(",");
sb.append(V15).append(",");
sb.append(V16).append(",");
sb.append(V17).append(",");
sb.append(V18).append(",");
sb.append(V19).append(",");
sb.append(V20).append(",");
sb.append(V21).append(",");
sb.append(V22).append(",");
sb.append(V23).append(",");
sb.append(V24).append(",");
sb.append(V25).append(",");
sb.append(V26).append(",");
sb.append(V27).append(",");
sb.append(V28).append(",");
sb.append(AmountScaler).append(",");
sb.append(Class);
return sb.toString();
}
public static DataCredit instanceFromString(String line) {
String[] tokens = line.split(",");
if (tokens.length != 31) {
System.out.println("#############Invalid record: " + line+"\n");
//return null;
//throw new RuntimeException("Invalid record: " + line);
}
DataCredit diag = new DataCredit();
try {
diag.Time = tokens[0].length() > 0 ? Double.parseDouble(tokens[0].trim()):null;
diag.V1 = tokens[1].length() > 0 ? Double.parseDouble(tokens[1]):null;
diag.V2 = tokens[2].length() > 0 ? Double.parseDouble(tokens[2]): null;
diag.V3 = tokens[3].length() > 0 ? Double.parseDouble(tokens[3]) : null;
diag.V4 = tokens[4].length() > 0 ? Double.parseDouble(tokens[4]) : null;
diag.V5 = tokens[5].length() > 0 ? Double.parseDouble(tokens[5]): null;
diag.V6 =tokens[6].length() > 0 ? Double.parseDouble(tokens[6]) : null;
diag.V7 = tokens[7].length() > 0 ? Double.parseDouble(tokens[7]) : null;
diag.V8 = tokens[8].length() > 0 ? Double.parseDouble(tokens[8]) : null;
diag.V9 = tokens[9].length() > 0 ? Double.parseDouble(tokens[9]) : null;
diag.V10 = tokens[10].length() > 0 ? Double.parseDouble(tokens[10]) : null;
diag.V11 = tokens[11].length() > 0 ? Double.parseDouble(tokens[11]) : null;
diag.V12 = tokens[12].length() > 0 ? Double.parseDouble(tokens[12]) : null;
diag.V13 = tokens[13].length() > 0 ? Double.parseDouble(tokens[13]) : null;
diag.V14 = tokens[14].length() > 0 ? Double.parseDouble(tokens[14]) : null;
diag.V15 = tokens[15].length() > 0 ? Double.parseDouble(tokens[15]) : null;
diag.V16 = tokens[16].length() > 0 ? Double.parseDouble(tokens[16]) : null;
diag.V17 = tokens[17].length() > 0 ? Double.parseDouble(tokens[17]) : null;
diag.V18 = tokens[18].length() > 0 ? Double.parseDouble(tokens[18]) : null;
diag.V19 = tokens[19].length() > 0 ? Double.parseDouble(tokens[19]) : null;
diag.V20 = tokens[20].length() > 0 ? Double.parseDouble(tokens[20]) : null;
diag.V21 = tokens[21].length() > 0 ? Double.parseDouble(tokens[21]) : null;
diag.V22 = tokens[22].length() > 0 ? Double.parseDouble(tokens[22]) : null;
diag.V23 = tokens[23].length() > 0 ? Double.parseDouble(tokens[23]) : null;
diag.V24 = tokens[24].length() > 0 ? Double.parseDouble(tokens[24]) : null;
diag.V25 = tokens[25].length() > 0 ? Double.parseDouble(tokens[25]) : null;
diag.V26 = tokens[26].length() > 0 ? Double.parseDouble(tokens[26]) : null;
diag.V27 = tokens[27].length() > 0 ? Double.parseDouble(tokens[27]) : null;
diag.V28 = tokens[28].length() > 0 ? Double.parseDouble(tokens[28]) : null;
diag.Amount = tokens[29].length() > 0 ? Double.parseDouble(tokens[29]) : null;
diag.Class = tokens[30].length() > 0 ? Double.parseDouble(tokens[30]) : null;
} catch (NumberFormatException nfe) {
throw new RuntimeException("Invalid record: " + line, nfe);
}
return diag;
}
public long getEventTime() {
return this.eventTime.getMillis();
}
}
operating chain
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// operate in Event-time
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// start the data generator
DataStream<DataCredit> DsHeart = env.addSource(
new CreditSource(input, servingSpeedFactor));
DataStream<DataCredit> modDataStr = DsHeart
.filter(new NoneFilter())
.map(new mapTime()).keyBy(0)
.flatMap(new NullFillMean());
DataStream<String> modFraudStrForLR =modDataStr.filter(new FraudFilter()).flatMap(new CreditFlatMapForLR());
DataStream<String> modNonFraudStrForLR =modDataStr.filter(new NonFraudFilter()).flatMap(new CreditFlatMapForLR());
//modDataStr2.print();
modFraudStrForLR.writeAsText("./CreditDataFraudForLR");
modNonFraudStrForLR.writeAsText("./CreditDataNonFraudForLR");
env.execute("HeartData Prediction");
非控值均值填充:
public static class NullFillMean extends RichFlatMapFunction<Tuple2<Long, DataCredit> ,DataCredit> {
//private transient ValueState<Double> heartMeanState;
private transient ListState<Double> ProductCategoryState;
private List<Double> meansList;
@Override
public void flatMap(Tuple2<Long, DataCredit> val, Collector< DataCredit> out) throws Exception {
Iterator<Double> modStateLst = ProductCategoryState.get().iterator();
Double MeanProductCategory1=null;
Double MeanProductCategory2=null;
if(!modStateLst.hasNext()){
MeanProductCategory1 = 0.55;
MeanProductCategory2 = 1.0;
}else{
MeanProductCategory1=modStateLst.next();
MeanProductCategory2=modStateLst.next();
}
DataCredit credit = val.f1;
if(credit.V16 == null){
credit.V16= MeanProductCategory1;
}else if(credit.V12 == null){
credit.V12= MeanProductCategory2;
}else
{
meansList= new ArrayList<Double>();
meansList.add(credit.V16);
meansList.add(credit.V12);
ProductCategoryState.update(meansList);
}
out.collect(credit);
}
@Override
public void open(Configuration config) {
ListStateDescriptor<Double> descriptor2 =
new ListStateDescriptor<>(
// state name
"regressionModel",
// type information of state
TypeInformation.of(Double.class));
ProductCategoryState = getRuntimeContext().getListState(descriptor2);
}
}保存为预期的文件格式
public static class CreditFlatMapForLR implements FlatMapFunction<DataCredit, String> {
@Override
public void flatMap(DataCredit InputDiag, Collector<String> collector) throws Exception {
DataCredit sale = InputDiag;
//sb.append(diag.date).append(",");
sale.TimeScalerParse();
sale.AmountParse();
collector.collect(sale.toString());
}
}文件结果保存样例:
0.09153780267604981,-4.64189285087538,2.90208643306647,-1.57293870931742,2.507298518227,-0.871782564349351,-1.0409025722626,-1.59390073966645,-3.25490508581579,1.90896268593707,1.07741752106048,3.33850216040272,-6.54261034532574,1.09953638182128,-3.26647554459315,1.01472790444294,-4.84238307827835,-5.269876299726,-2.34466857415508,1.95922405409272,-0.465679220344122,1.96359666634146,-0.217413915973245,-0.54933995583883,0.645545202036521,-0.354557818794591,-0.611763845006479,-3.90808047547799,-0.671248265147117,4.4334315772429116E-4,1.0
0.11580975971109773,-14.7246270119253,7.87515679273047,-21.8723173644566,11.9061699078901,-8.34873369160876,-2.26284641969245,-15.8334427819606,0.0778736741759969,-6.35683349086288,-13.2616517082667,10.0637897462894,-14.3947668016721,0.654888723464231,-14.2483158270781,-0.305360761401071,-8.16163244506225,-12.2809648581754,-4.81858639342974,0.719787682108791,0.996468755724792,-2.36234492751884,1.09955729576975,1.03719942301307,-1.03635934178889,-0.254776514154375,0.642343201018144,2.16112922373151,-1.40128201963858,3.892389444462609E-5,1.0
模型训练:
1. 定时任务分别监控欺诈和非欺诈结果的实时数据文件夹,统计非欺诈结果的数据集个数,用于resample模型训练数据集
2. 模型训练
object CreditDecisionTree {
case class Credit(
TimeScaler: Double,
V1: Double, V2: Double, V3: Double, V4: Double, V5: Double, V6: Double, V7: Double, V8: Double, V9: Double, V10:Double,
V11:Double, V12:Double, V13:Double, V14:Double, V15:Double, V16:Double, V17:Double, V18:Double, V19:Double, V20:Double,
V21:Double, V22:Double,V23:Double, V24:Double, V25:Double, V26:Double, V27:Double, V28:Double,
AmountScaler:Double, Class:Double
)
def parseCredit(line: Array[Double]): Credit = {
Credit(
line(0),
line(1) , line(2) , line(3) , line(4), line(5), line(6), line(7), line(8), line(9), line(10),
line(11), line(12), line(13),line(14), line(15), line(16), line(17),line(18), line(19), line(20),
line(21), line(22),line(23),line(24),line(25),line(26),line(27),line(28),
line(29),line(30)
)
}
//RDD转换函数:解析一行文件内容从String,转变为Array[Double]类型,并过滤掉缺失数据的行
def parseRDD(rdd: RDD[String]): RDD[Array[Double]] = {
//rdd.foreach(a=> print(a+"\n"))
val a=rdd.map(_.split(","))
a.map(_.map(_.toDouble)).filter(_.length==31)
}
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("sparkIris").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val data_path = "D:/code/flink/CreditDataNonFraudForLR/*"
val DF = parseRDD(sc.textFile(data_path)).map(parseCredit).toDF().cache()
val data_path2 = "D:/code/flink/CreditDataFraudForLR/*"
val DFFraud = parseRDD(sc.textFile(data_path2)).map(parseCredit).toDF().cache()
println(DF.count())
val DFNonFraud=DF.limit(DFFraud.count().toInt)
val df2=DFFraud.union(DFNonFraud)
println(DFNonFraud.count())
println(df2.count())
println(df2.filter(df2("Class")===0).show)
val featureCols1 = Array("TimeScaler",
"V1","V2","V3","V4","V5","V6","V7","V8","V9","V10",
"V11","V12","V13","V14","V15","V16","V17","V18","V19","V20",
"V21","V22","V23","V24","V25","V26","V27","V28",
"AmountScaler")
val label1="Class"
val mlUtil= new MLUtil()
mlUtil.DtClassifyBinary(df2,featureCols1,label1)
}
}
DtClassifyBinary 函数定义:
def DtClassifyBinary(df :DataFrame,featureCols1:Array[String],label :String ): Unit ={
val assembler = new VectorAssembler().setInputCols(featureCols1).setOutputCol("features")
val df2 = assembler.transform(df)
df2.show
val Array(trainingData, testData) = df2.randomSplit(Array(0.7, 0.3))
val classifier = new DecisionTreeClassifier()
.setLabelCol(label)
.setFeaturesCol("features")
.setImpurity("gini")
.setMaxDepth(5)
val model = classifier.fit(trainingData)
try {
// model.write.overwrite().save("D:\\code\\spark\\model\\spark-LF-Occupy")
// val sameModel = DecisionTreeClassificationModel.load("D:\\code\\spark\\model\\spark-LF-Occupy")
val predictions = model.transform(testData)
predictions.show()
val evaluator = new BinaryClassificationEvaluator().setLabelCol(label).setRawPredictionCol("prediction")
val accuracy = evaluator.evaluate(predictions)
println("accuracy fitting: " + accuracy)
}catch{
case ex: Exception =>println(ex)
case ex: Throwable =>println("found a unknown exception"+ ex)
}
}
模型评估效果:
accuracy fitting: 0.9892760723927607
没有评论