项目说明:
根据用户购物行为发现一些特征相关性,并做一些分类预测或者聚类;
比如预测客户的年龄,预测用户购买物品的种类,比如基于用户的聚类等
数据源
来自零售商店的事物数据
User_ID: Unique identifier of shopper.
Product_ID: Unique identifier of product. (No key given)
Gender: Sex of shopper.
Age: Age of shopper split into bins.
Occupation: Occupation of shopper. (No key given)
City_Category: Residence location of shopper. (No key given)
Stay_In_Current_City_Years: Number of years stay in current city.
Marital_Status: Marital status of shopper.
Product_Category_1: Product category of purchase.
Product_Category_2: Product may belong to other category.
Product_Category_3: Product may belong to other category.
Purchase: Purchase amount in dollars.
| User_ID | Product_ID | Gender | Age | Occupation | City_Category | Stay_In_Current_City_Years | Marital_Status | Product_Category_1 | Product_Category_2 | Product_Category_3 | Purchase |
| 1000001 | P00069042 | F | 0-17 | 10 | A | 2 | 0 | 3 | 8370 | ||
| 1000001 | P00248942 | F | 0-17 | 10 | A | 2 | 0 | 1 | 6 | 14 | 15200 |
| 1000001 | P00087842 | F | 0-17 | 10 | A | 2 | 0 | 12 | 1422 | ||
| 1000001 | P00085442 | F | 0-17 | 10 | A | 2 | 0 | 12 | 14 | 1057 | |
| 1000002 | P00285442 | M | 55+ | 16 | C | 4+ | 0 | 8 | 7969 | ||
| 1000003 | P00193542 | M | 26-35 | 15 | A | 3 | 0 | 1 | 2 | 15227 | |
| 1000004 | P00184942 | M | 46-50 | 7 | B | 2 | 1 | 1 | 8 | 17 | 19215 |
数据探索:
数据分布情况—数值型:
大部分购买金额为12073左右
User_ID Occupation Marital_Status Product_Category_1 Product_Category_2 Product_Category_3 Purchase count 5.375770e+05 537577.00000 537577.000000 537577.000000 370591.000000 164278.000000 537577.000000 mean 1.002992e+06 8.08271 0.408797 5.295546 9.842144 12.669840 9333.859853 std 1.714393e+03 6.52412 0.491612 3.750701 5.087259 4.124341 4981.022133 min 1.000001e+06 0.00000 0.000000 1.000000 2.000000 3.000000 185.000000 25% 1.001495e+06 2.00000 0.000000 1.000000 5.000000 9.000000 5866.000000 50% 1.003031e+06 7.00000 0.000000 5.000000 9.000000 14.000000 8062.000000 75% 1.004417e+06 14.00000 1.000000 8.000000 15.000000 16.000000 12073.000000 max 1.006040e+06 20.00000 1.000000 18.000000 18.000000 18.000000 23961.000000
数据分布情况–非数值型:
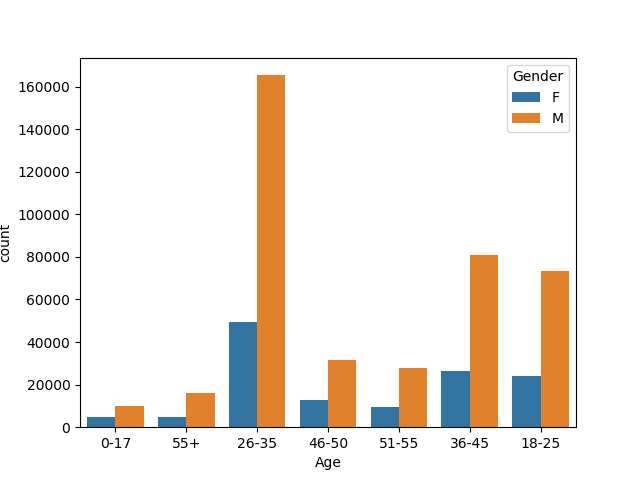
购买力大部分来自男性
消费欲望最强的年龄阶段是26-35
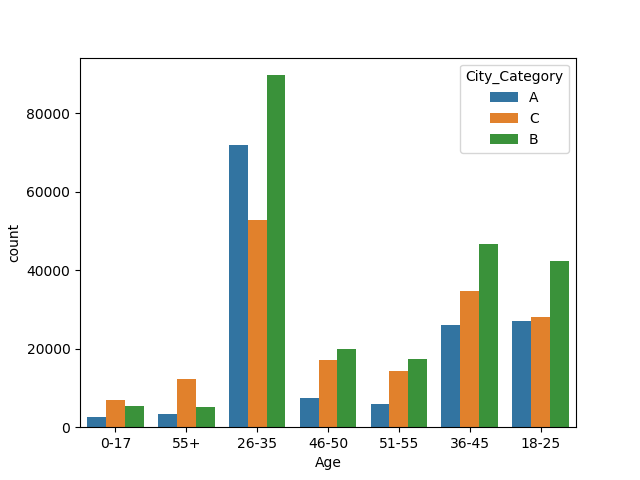
城市类型为B
大部分客户在当前城市只待了1年左右
Product_ID Gender Age City_Category Stay_In_Current_City_Years count 537577 537577 537577 537577 537577 unique 3623 2 7 3 5 top P00265242 M 26-35 B 1 freq 1858 405380 214690 226493 189192
各特征类型和非空情况统计:
部分值会出现空值,做空值判断处理
数据类型较多,部分数值类型中参杂非数值类型,比如Stay_In_Current_City_Years
Product_Category_3 的空值太多,考虑直接删除该特征
Product_Category_2 考虑使用均值填充
Data columns (total 12 columns):
User_ID 537577 non-null int64
Product_ID 537577 non-null object
Gender 537577 non-null object
Age 537577 non-null object
Occupation 537577 non-null int64
City_Category 537577 non-null object
Stay_In_Current_City_Years 537577 non-null object
Marital_Status 537577 non-null int64
Product_Category_1 537577 non-null int64
Product_Category_2 370591 non-null float64
Product_Category_3 164278 non-null float64
Purchase 537577 non-null int64
特征相关性—数值型
特别相关的特征不太多
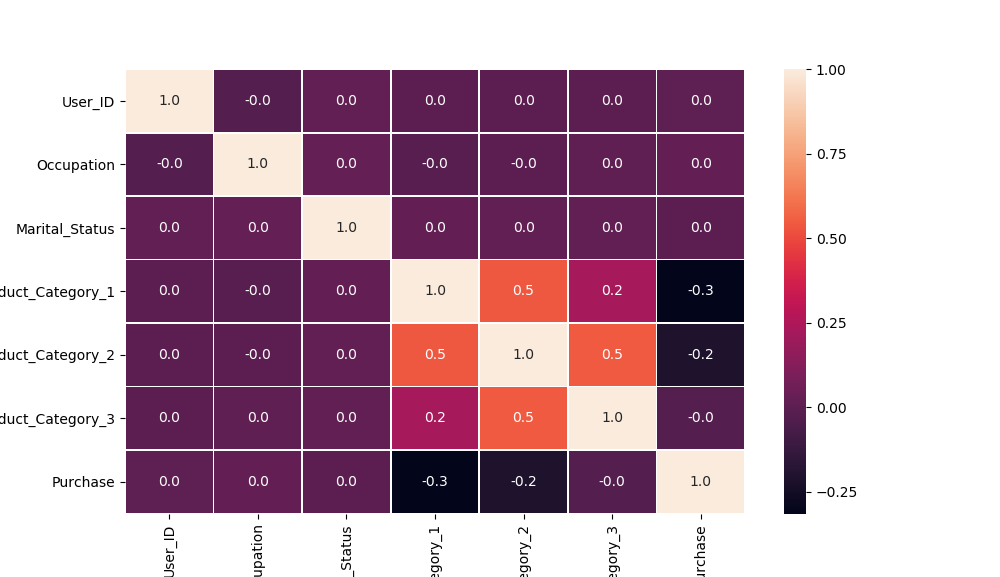
特征相关性—非数值型
sns.countplot(df['Age'],hue=df['Gender'])
plt.show( )age & gender
age &City_Category
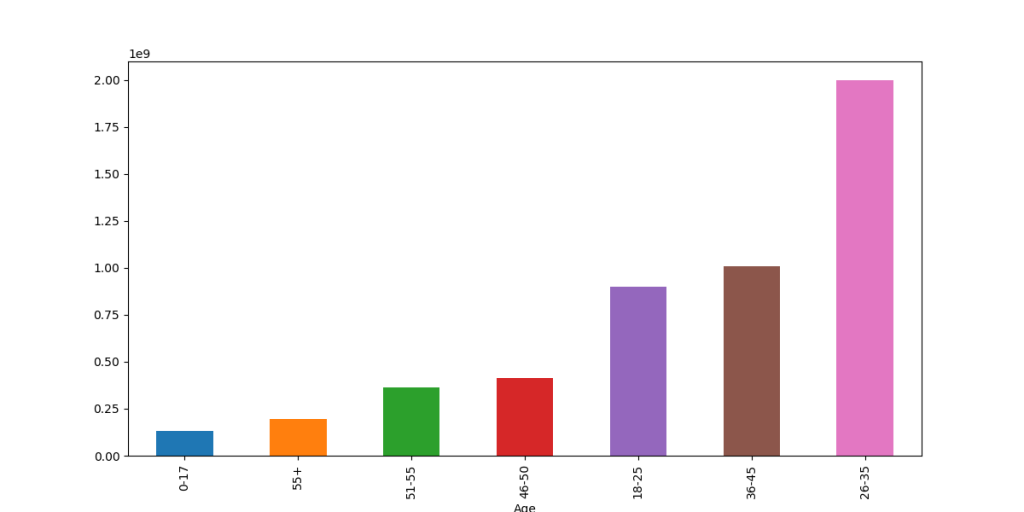
age & Purchase
Purchase &Stay_In_Current_City_Years
plot('Stay_In_Current_City_Years','Purchase','bar')
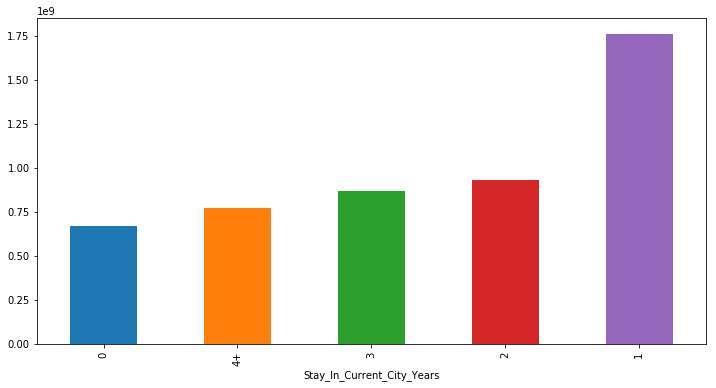
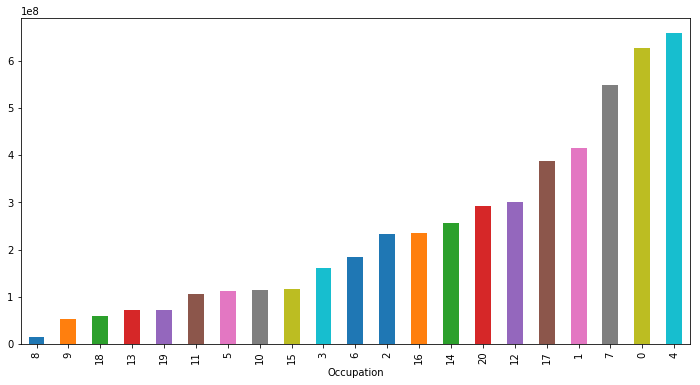
Purchase&Occupation
plot('Occupation','Purchase','bar')
Purchase&Products
plot('Product_Category_1','Purchase','barh')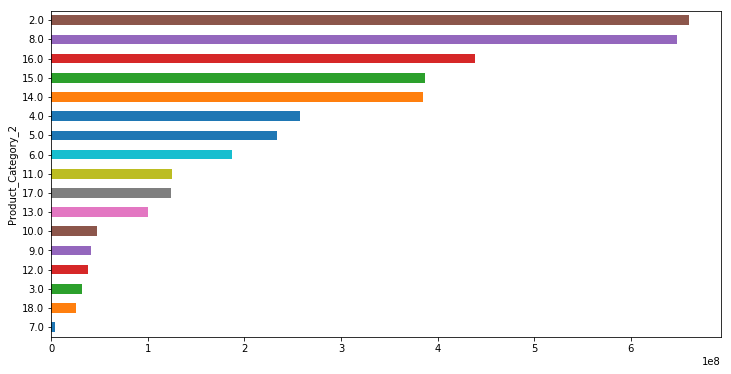
plot('Product_Category_2','Purchase','barh')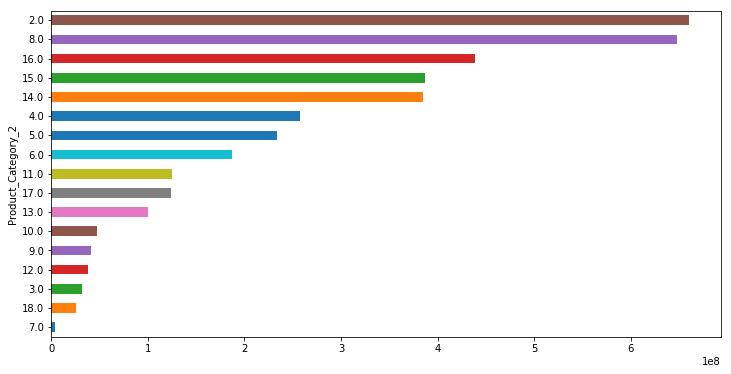
plot('Product_Category_3','Purchase','barh')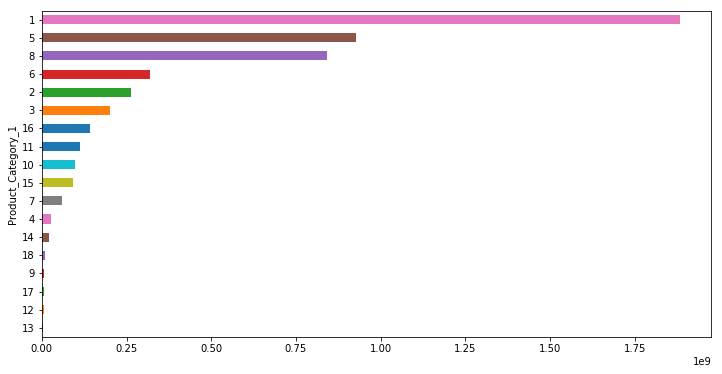
由上述分析可知很多特征和age 有相关性,可以以它们为标签做分类预测
和 Purchase的相关性特征也有,但单位都比较小,影响不太大,做回归的效果可能不太好
特征数据处理:
主要处理内容:
- 空值处理:空值比较少情况可以考虑删除或者均值填充
- 异常值处理— 与均值差别太大的值删除
- 个别变量需要哑变量化处理:Age,City_Category,Stay_In_Current_City_Years
- 标签特征数值化处理:Age(因为需要用于做预测标签,所以需要数值化处理)
数据结构类定义:
把哑变量特征也加入到该结构中,并包括特征哑变量化的成员函数
public class DataFriday implements Serializable {
public String User_ID;
public String Product_ID;
public String Gender;
public Integer Male;
public Integer Female;
public String Age;
public Integer AgeLabel;//用于模型训练时作为标签列的数值型
public Integer AgeTeenager;//0-17
public Integer AgeYoung1;//18-25
public Integer AgeYoung2;//26-35
public Integer AgeMid;//36-45
public Integer AgeOld1;//46-50
public Integer AgeOld2;//51-55
public Integer AgeOld3;//55+
public Integer Occupation;
public String City_Category;
public Integer CityA;
public Integer CityB;
public Integer CityC;
public String Stay_In_Current_City_Years;
public Integer StayYears1;
public Integer StayYears2;
public Integer StayYears3;
public Integer StayYearsMoreThen4;
public Integer Marital_Status;
public Integer Product_Category_1;
public Integer Product_Category_2;
public Integer Product_Category_3;
public Float Purchase;
public DateTime eventTime;
public DataFriday() {
this.eventTime = new DateTime();
}
public DataFriday(String User_ID, String Product_ID, String Gender, String Age, Integer Occupation, String City_Category, String Stay_In_Current_City_Years,
int Marital_Status, int Product_Category_1, int Product_Category_2, int Product_Category_3, Float Purchase) {
this.eventTime = new DateTime();
this.User_ID = User_ID;
this.Product_ID = Product_ID;
this.Gender = Gender;
this.Age = Age;
this.Occupation = Occupation;
this.City_Category = City_Category;
this.Stay_In_Current_City_Years = Stay_In_Current_City_Years;
this.Marital_Status = Marital_Status;
this.Product_Category_1 = Product_Category_1;
this.Product_Category_2 = Product_Category_2;
this.Product_Category_3 = Product_Category_3;
this.Purchase = Purchase;
}
public void GenderParse(){
if ("M".equals(this.Gender)){
this.Male=1;
this.Female=0;
}else{
this.Male=0;
this.Female=1;
}
}
public void CityCategoryParse(){
this.CityA=0;
this.CityB=0;
this.CityC=0;
if ("A".equals(this.City_Category)){
this.CityA=1;
}else if ("B".equals(this.City_Category)){
this.CityB=1;
}else{
this.CityC=1;
}
}
public void StayYearsParse(){
this.StayYears1=0;
this.StayYears2=0;
this.StayYears3=0;
this.StayYearsMoreThen4=0;
if ("1".equals(this.StayYears1)){
this.StayYears1=1;
}else if ("2".equals(this.StayYears2)){
this.StayYears2=1;
}else if ("3".equals(this.StayYears3)){
this.StayYears3=1;
}else{
this.StayYearsMoreThen4=1;
}
}
public void AgeParse(){
this.AgeTeenager=0;//0-17
this.AgeYoung1=0;//18-25
this.AgeYoung2=0;//26-35
this.AgeMid=0;//36-45
this.AgeOld1=0;//36-45
this.AgeOld2=0;//36-45
this.AgeOld3=0;//36-45
this.AgeLabel=0;
if ("0-17".equals(this.Age)){
this.AgeTeenager=1;
}else if("18-25".equals(this.Age)){
this.AgeYoung1=1;
this.AgeLabel=1;
}else if("26-35".equals(this.Age)){
this.AgeYoung2=1;
this.AgeLabel=2;
}else if("36-45".equals(this.Age)){
this.AgeMid=1;
this.AgeLabel=3;
}else if("46-50".equals(this.Age)){
this.AgeOld1=1;
this.AgeLabel=4;
}else if("51-55".equals(this.Age)){
this.AgeOld2=1;
this.AgeLabel=5;
}else if("55+".equals(this.Age)){
this.AgeOld3=1;
this.AgeLabel=6;
}
}
//输出列包括新增的哑变量列
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(AgeLabel).append(",");
sb.append(Male).append(",");
sb.append(Female).append(",");
sb.append(AgeTeenager).append(",");
sb.append(AgeYoung1).append(",");
sb.append(AgeYoung2).append(",");
sb.append(AgeMid).append(",");
sb.append(AgeOld1).append(",");
sb.append(AgeOld2).append(",");
sb.append(AgeOld3).append(",");
sb.append(Occupation).append(",");
sb.append(CityA).append(",");
sb.append(CityB).append(",");
sb.append(CityC).append(",");
sb.append(StayYears1).append(",");
sb.append(StayYears2).append(",");
sb.append(StayYears3).append(",");
sb.append(StayYearsMoreThen4).append(",");
sb.append(Marital_Status).append(",");
sb.append(Product_Category_1).append(",");
sb.append(Product_Category_2).append(",");
//sb.append(Product_Category_3).append(",");
sb.append(Purchase);
return sb.toString();
}
public static DataFriday instanceFromString(String line) {
String[] tokens = line.split(",");
if (tokens.length != 12) {
System.out.println("#############Invalid record: " + line+"\n");
//return null;
//throw new RuntimeException("Invalid record: " + line);
}
DataFriday diag = new DataFriday();
try {
diag.User_ID = tokens[0].length() > 0 ? tokens[0].trim():null;
diag.Product_ID = tokens[1].length() > 0 ? tokens[1]:null;
diag.Gender = tokens[2].length() > 0 ? tokens[2]: null;
diag.Age = tokens[3].length() > 0 ? tokens[3] : null;
diag.Occupation = tokens[4].length() > 0 ? Integer.parseInt(tokens[4]) : null;
diag.City_Category = tokens[5].length() > 0 ? tokens[5]: null;
diag.Stay_In_Current_City_Years =tokens[6].length() > 0 ? tokens[6] : null;
diag.Marital_Status = tokens[7].length() > 0 ? Integer.parseInt(tokens[7]) : null;
diag.Product_Category_1 = tokens[8].length() > 0 ? Integer.parseInt(tokens[8]) : null;
diag.Product_Category_2 = tokens[9].length() > 0 ? Integer.parseInt(tokens[9]) : null;
diag.Product_Category_3 = tokens[10].length() > 0 ? Integer.parseInt(tokens[10]) : null;
diag.Purchase = tokens[11].length() > 0 ? Float.parseFloat(tokens[11]) : null;
} catch (NumberFormatException nfe) {
throw new RuntimeException("Invalid record: " + line, nfe);
}
return diag;
}
public long getEventTime() {
return this.eventTime.getMillis();
}
}
定义Source
由于大部分source内容类似,我们抽象出一个BaseSource类,大部分相同的操作都在该类中实现:
实现类重写Run函数
public class FridaySource extends BaseSource<DataFriday> {
public FridaySource(String dataFilePath) {
super(dataFilePath, 1);
}
public FridaySource(String dataFilePath, int servingSpeedFactor) {
super(dataFilePath,servingSpeedFactor);
}
public long getEventTime(DataFriday diag) {
return diag.getEventTime();
}
@Override
public void run(SourceContext<DataFriday> sourceContext) throws Exception {
super.FStream = new FileInputStream(super.dataFilePath);
super.reader = new BufferedReader(new InputStreamReader(super.FStream, "UTF-8"));
String line;
long time;
while (super.reader.ready() && (line = super.reader.readLine()) != null) {
DataFriday diag = DataFriday.instanceFromString(line);
if (diag == null){
continue;
}
time = getEventTime(diag);
sourceContext.collectWithTimestamp(diag, time);
sourceContext.emitWatermark(new Watermark(time - 1));
}
super.reader.close();
super.reader = null;
super.FStream.close();
super.FStream = null;
}
}
定义Operation Chain:
注意导入文件编码格式,一定要是utf-8格式编码!
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// operate in Event-time
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// start the data generator
DataStream<DataFriday> DsHeart = env.addSource(
new FridaySource(input, servingSpeedFactor));
DataStream<String> modDataStrForLR = DsFriday
.filter(new NoneFilter())
.map(new mapTime()).keyBy(0)
.flatMap(new NullFillMean())
.flatMap(new heartFlatMapForLR());
//modDataStrForLR.print();
modDataStrForLR.writeAsText("./FridayDataForLR");
// run the prediction pipeline
env.execute("FridayData Prediction");
定义部分特征空值过滤 Operation类:
public static class NoneFilter implements FilterFunction<DataFriday> {
@Override
public boolean filter(DataFriday sale) throws Exception {
return IsNotNone(sale.Age) && IsNotNone(sale.Purchase) &&IsNotNone(sale.User_ID)
&& IsNotNone(sale.Product_ID) ;
}
public boolean IsNotNone(Object Data){
if (Data == null )
return false;
else
return true;
}
}
定义空值预测Flatmap Operation 类:
对空值使用均值填充,这里使用ListState 结构保存多个特征的均值;
public static class NullFillMean extends RichFlatMapFunction<Tuple2<Long, DataFriday> ,DataFriday> {
private transient ListState<Double> ProductCategoryState;
private List<Double> meansList;
@Override
public void flatMap(Tuple2<Long, DataFriday> val, Collector< DataFriday> out) throws Exception {
Iterator<Double> modStateLst = ProductCategoryState.get().iterator();
Double MeanProductCategory1=null;
Double MeanProductCategory2=null;
if(!modStateLst.hasNext()){
MeanProductCategory1 = 8.0;
MeanProductCategory2 = 15.0;
}else{
MeanProductCategory1=modStateLst.next();
MeanProductCategory2=modStateLst.next();
}
meansList= new ArrayList<Double>();
meansList.add(MeanProductCategory1);
meansList.add(MeanProductCategory2);
DataFriday heart = val.f1;
if(heart.Product_Category_1 == null){
heart.Product_Category_1= Math.toIntExact(Math.round(MeanProductCategory1));
out.collect(heart);
}else if(heart.Product_Category_2 == null){
heart.Product_Category_2= Math.toIntExact(Math.round(MeanProductCategory2));;
out.collect(heart);
}else
{
ProductCategoryState.update(meansList);
out.collect(heart);
}
}
@Override
public void open(Configuration config) {
ListStateDescriptor<Double> descriptor2 =
new ListStateDescriptor<>(
// state name
"regressionModel",
// type information of state
TypeInformation.of(Double.class));
ProductCategoryState = getRuntimeContext().getListState(descriptor2);
}
}
定义 保存特定列特定文件格式的flatmap operation:
兼顾 部分数值特征 哑变量化功能,哑变量处理函数定义在DataFriday类中
public static class heartFlatMapForLR implements FlatMapFunction<DataFriday, String> {
@Override
public void flatMap(DataFriday InputDiag, Collector<String> collector) throws Exception {
DataFriday sale = InputDiag;
StringBuilder sb = new StringBuilder();
//sb.append(diag.date).append(",");
sale.AgeParse();
sale.GenderParse();
sale.CityCategoryParse();
sale.StayYearsParse();
collector.collect(sale.toString());
}
}
保存到CSV文件中样例:
4,1,0,0,0,0,0,1,0,0,7,0,1,0,0,0,0,1,1,1,8,19215.0 5,0,1,0,0,0,0,0,1,0,9,1,0,0,0,0,0,1,0,5,8,5378.0 2,1,0,0,0,1,0,0,0,0,12,0,0,1,0,0,0,1,1,8,15,9743.0
Spark 定时任务训练模型:
这里使用DecisionTree模型,通过使用所有其他列特征预测客户的Age
object FridayDecisionTree {
case class Friday(
AgeLabel: Double, Male: Double, Female: Double, AgeTeenager: Double, AgeYoung1: Double, AgeYoung2: Double, AgeMid: Double, AgeOld1: Double, AgeOld2: Double, AgeOld3: Double,
Occupation:Double, CityA:Double, CityB:Double, CityC:Double, StayYears1:Double, StayYears2:Double, StayYears3:Double,
StayYearsMoreThen4:Double, Marital_Status:Double, Product_Category_1:Double, Product_Category_2:Double, Purchase:Double
)
//解析一行event内容,并映射为Diag类
def parseFriday(line: Array[Double]): Friday = {
Friday(
line(0), line(1) , line(2) , line(3) , line(4), line(5), line(6), line(7), line(8), line(9), line(10),
line(11), line(12), line(13),line(14), line(15), line(16), line(17),line(18), line(19), line(20), line(21)
)
}
//RDD转换函数:解析一行文件内容从String,转变为Array[Double]类型,并过滤掉缺失数据的行
def parseRDD(rdd: RDD[String]): RDD[Array[Double]] = {
//rdd.foreach(a=> print(a+"\n"))
val a=rdd.map(_.split(","))
a.map(_.map(_.toDouble)).filter(_.length==22)
}
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("sparkIris").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val data_path = "D:/code/flink-training-exercises-master/FridayDataForLR/*"
val DF = parseRDD(sc.textFile(data_path)).map(parseFriday).toDF().cache()
println(DF.count())
val featureCols1 = Array("Male","Female", "Occupation",
"CityA","CityB","CityC","StayYears1","StayYears2","StayYears3",
"StayYearsMoreThen4","Marital_Status","Product_Category_1","Product_Category_2","Purchase")
val label1="AgeLabel"
val featureCols2 = Array("Male","Female", "AgeTeenager", "AgeYoung1", "AgeYoung2","AgeMid", "AgeOld1", "AgeOld2", "AgeOld3","Occupation",
"CityA","CityB","CityC","StayYears1","StayYears2","StayYears3",
"StayYearsMoreThen4","Marital_Status","Product_Category_1","Product_Category_2")
val label2="Purchase"
val mlUtil= new MLUtil()
mlUtil.decisionTree(DF,featureCols1,label1)
mlUtil.linearRegression(DF,featureCols2,label2,"./model/spark-LR-model-friday")
}
}
定义ML算法封装类:
class MLUtil {
def decisionTree(df :DataFrame,featureCols1:Array[String],label :String ): Unit ={
val assembler = new VectorAssembler().setInputCols(featureCols1).setOutputCol("features")
val df2 = assembler.transform(df)
df2.show
val Array(trainingData, testData) = df2.randomSplit(Array(0.7, 0.3))
//val classifier = new RandomForestClassifier()
val classifier = new DecisionTreeClassifier()
.setLabelCol(label)
.setFeaturesCol("features")
.setImpurity("gini")
.setMaxDepth(5)
val model = classifier.fit(trainingData)
try {
// model.write.overwrite().save("D:\\code\\spark\\model\\spark-LF-Occupy")
// val sameModel = DecisionTreeClassificationModel.load("D:\\code\\spark\\model\\spark-LF-Occupy")
val predictions = model.transform(testData)
predictions.show()
val evaluator = new BinaryClassificationEvaluator().setLabelCol(label).setRawPredictionCol("prediction")
val accuracy = evaluator.evaluate(predictions)
println("accuracy fitting: " + accuracy)
}catch{
case ex: Exception =>println(ex)
case ex: Throwable =>println("found a unknown exception"+ ex)
}
}
def linearRegression(df:DataFrame,featureCols:Array[String], label:String,modPath:String): Unit ={
val assembler = new VectorAssembler().setInputCols(featureCols).setOutputCol("features")
val df2 = assembler.transform(df)
df2.show
val splitSeed = 5043
val Array(trainingData, testData) = df2.randomSplit(Array(0.7, 0.3), splitSeed)
val classifier = new LinearRegression().setFeaturesCol("features").setLabelCol(label).setFitIntercept(true).setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)
val model = classifier.fit(trainingData)
// 输出模型全部参数
model.extractParamMap()
// Print the coefficients and intercept for linear regression
println(s"Coefficients: ${model.coefficients} Intercept: ${model.intercept}")
val predictions = model.transform(trainingData)
predictions.selectExpr(label, "round(prediction,1) as prediction").show
// 模型进行评价
val trainingSummary = model.summary
val rmse =trainingSummary.rootMeanSquaredError
println(s"RMSE: ${rmse}")
println(s"r2: ${trainingSummary.r2}")
//val predictions = model.transform(testData)
if (rmse <0.3) {
try {
model.write.overwrite().save(modPath)//"./model/spark-LR-model-energy")
val sameModel = LinearRegressionModel.load(modPath)//"./model/spark-LR-model-energy")
val predictions= sameModel.transform(testData)
predictions.show(3)
} catch {
case ex: Exception => println(ex)
case ex: Throwable => println("found a unknown exception" + ex)
}
}
}
def RFClassify(df:DataFrame,featureCols:Array[String], label:String,modPath:String): Unit ={
val assembler = new VectorAssembler().setInputCols(featureCols).setOutputCol("features")
val df2 = assembler.transform(df)
val splitSeed = 5043
val Array(trainingData, testData) = df2.randomSplit(Array(0.7, 0.3), splitSeed)
//定义算法分类器,并训练模型
val classifier = new RandomForestClassifier().setFeaturesCol("features").setLabelCol(label)
//定义评估器---多元分类评估(label列与Prediction列对比结果)
//val evaluator:Evaluator=null
val evaluator = new MulticlassClassificationEvaluator().setLabelCol(label).setPredictionCol("prediction")
//定义算法变量调试范围
val paramGrid = new ParamGridBuilder()
.addGrid(classifier.maxBins, Array(25, 31))
.addGrid(classifier.maxDepth, Array(5, 10))
.addGrid(classifier.numTrees, Array(2, 8))
.addGrid(classifier.impurity, Array("entropy", "gini"))
.build()
//定义算法pipeline ,stage集合
val steps: Array[PipelineStage] = Array(classifier)
val pipeline = new Pipeline().setStages(steps)
//定义交叉验证器CrossValidator
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(10)
//pipeline执行,开始训练模型
val pipelineFittedModel = cv.fit(trainingData)
//对测试数据做预测
val predictions = pipelineFittedModel.transform(testData)
predictions.show(40)
val accuracy = evaluator.evaluate(predictions)
println("accuracy pipeline fitting:" + accuracy)
println(pipelineFittedModel.bestModel.asInstanceOf[org.apache.spark.ml.PipelineModel].stages(0))
if (accuracy >0.8) {
try {
pipelineFittedModel.write.overwrite().save(modPath)//"./model/spark-LR-model-diag")
} catch {
case ex: Exception => println(ex)
case ex: Throwable => println("found a unknown exception" + ex)
}
}
}
def RFReg(df:DataFrame,featureCols:Array[String], label:String,modPath:String): Unit ={
val assembler = new VectorAssembler().setInputCols(featureCols).setOutputCol("features")
val df2 = assembler.transform(df)
//向量化处理---Label向量化
// val labelIndexer = new StringIndexer().setInputCol("decision").setOutputCol("label")
// val df3 = labelIndexer.fit(df2).transform(df2)
val splitSeed = 5043
val Array(trainingData, testData) = df2.randomSplit(Array(0.7, 0.3), splitSeed)
//定义算法分类器,并训练模型
val classifier =new RandomForestRegressor().setFeaturesCol("features").setLabelCol(label)
//定义评估器---多元分类评估(label列与Prediction列对比结果)
//val evaluator:Evaluator=null
val evaluator = new RegressionEvaluator().setLabelCol(label).setPredictionCol("prediction").setMetricName("rmse")
//定义算法变量调试范围
val paramGrid = new ParamGridBuilder()
.addGrid(classifier.maxBins, Array(25, 31))
.addGrid(classifier.maxDepth, Array(5, 10))
.addGrid(classifier.numTrees, Array(2, 8))
.addGrid(classifier.impurity, Array("variance"))
.build()
//定义算法pipeline ,stage集合
val steps: Array[PipelineStage] = Array(classifier)
val pipeline = new Pipeline().setStages(steps)
//定义交叉验证器CrossValidator
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(10)
//pipeline执行,开始训练模型
val pipelineFittedModel = cv.fit(trainingData)
//对测试数据做预测
val predictions = pipelineFittedModel.transform(testData)
predictions.show(40)
val accuracy = evaluator.evaluate(predictions)
println("accuracy pipeline fitting:" + accuracy)
println(pipelineFittedModel.bestModel.asInstanceOf[org.apache.spark.ml.PipelineModel].stages(0))
if (accuracy >0.8) {
try {
pipelineFittedModel.write.overwrite().save(modPath)//"./model/spark-LR-model-diag")
// val sameModel = RandomForestModel.load("./model/spark-LR-model-diag")
// val predictions= sameModel.transform(testData)
//
// predictions.show(3)
} catch {
case ex: Exception => println(ex)
case ex: Throwable => println("found a unknown exception" + ex)
}
}
}
}
特征化后的df打印:
+--------+----+------+-----------+---------+---------+------+-------+-------+-------+----------+-----+-----+-----+----------+----------+----------+------------------+--------------+------------------+------------------+--------+--------------------+--------------------+--------------------+----------+
|AgeLabel|Male|Female|AgeTeenager|AgeYoung1|AgeYoung2|AgeMid|AgeOld1|AgeOld2|AgeOld3|Occupation|CityA|CityB|CityC|StayYears1|StayYears2|StayYears3|StayYearsMoreThen4|Marital_Status|Product_Category_1|Product_Category_2|Purchase| features| rawPrediction| probability|prediction|
+--------+----+------+-----------+---------+---------+------+-------+-------+-------+----------+-----+-----+-----+----------+----------+----------+------------------+--------------+------------------+------------------+--------+--------------------+--------------------+--------------------+----------+
| 0.0| 0.0| 1.0| 1.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 1.0| 0.0| 0.0| 0.0| 1.0| 0.0| 1.0| 6.0| 19506.0|(14,[1,5,9,11,12,...|[621.0,1446.0,307...|[0.07732536421367...| 2.0|
| 0.0| 0.0| 1.0| 1.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 1.0| 0.0| 0.0| 0.0| 1.0| 0.0| 1.0| 8.0| 19447.0|(14,[1,5,9,11,12,...|[621.0,1446.0,307...|[0.07732536421367...| 2.0|
模型效果评估打印:
Age预测模型:
accuracy fitting: 0.8562655906027428
Purchase 线性回归模型:
误差率有点高,和kaggle上其他人的结果差异不大,原因:
a. R2小说明和数据集相关性不高有关系
b. RMSE 大说明和Purchase的数据值比较大有关
+--------+----------+
|Purchase|prediction|
+--------+----------+
| 19506.0| 10878.4|
| 19447.0| 10597.1|
| 7974.0| 10390.0|
| 2081.0| 10075.5|
| 756.0| 9653.5|
| 5270.0| 9339.0|
| 5365.0| 8917.0|
| 8623.0| 8917.0|
| 1805.0| 8495.1|
| 5205.0| 8495.1|
| 5301.0| 8495.1|
| 6916.0| 8495.1|
| 7093.0| 8495.1|
| 3458.0| 8354.4|
| 5184.0| 8354.4|
| 8722.0| 8354.4|
| 8114.0| 7692.2|
| 7924.0| 7551.5|
| 7995.0| 7551.5|
| 4014.0| 7410.9|
+--------+----------+
only showing top 20 rows
RMSE: 4674.047671680409
r2: 0.11919367464012032考虑把Purchase 单位变大,值变小,虽然RMSE变小了,但是R2值依然不够理想,还是数据集Purchase与其他特征相关性不够的问题
+-------------+----------+
|PurchaseLabel|prediction|
+-------------+----------+
| 8.0| 10.4|
| 13.0| 10.2|
| 1.0| 9.2|
| 7.0| 9.2|
| 5.0| 8.9|
| 5.0| 8.6|
| 5.0| 8.5|
| 7.0| 8.5|
| 5.0| 7.8|
| 6.0| 7.7|
| 7.0| 7.7|
| 7.0| 7.7|
| 8.0| 7.7|
| 4.0| 7.0|
| 1.0| 6.7|
| 17.0| 5.8|
| 15.0| 11.0|
| 19.0| 11.0|
| 19.0| 11.0|
| 19.0| 11.0|
+-------------+----------+
only showing top 20 rows
RMSE: 4.71803386227115
r2: 0.10800711658827733把所有数值化后的特征再做一次相关性分析:
除了age和其他特征相关性比较大,
marital_status也和部分特征有一定相关性,但不是很明显,可以考虑将其作为预测对象
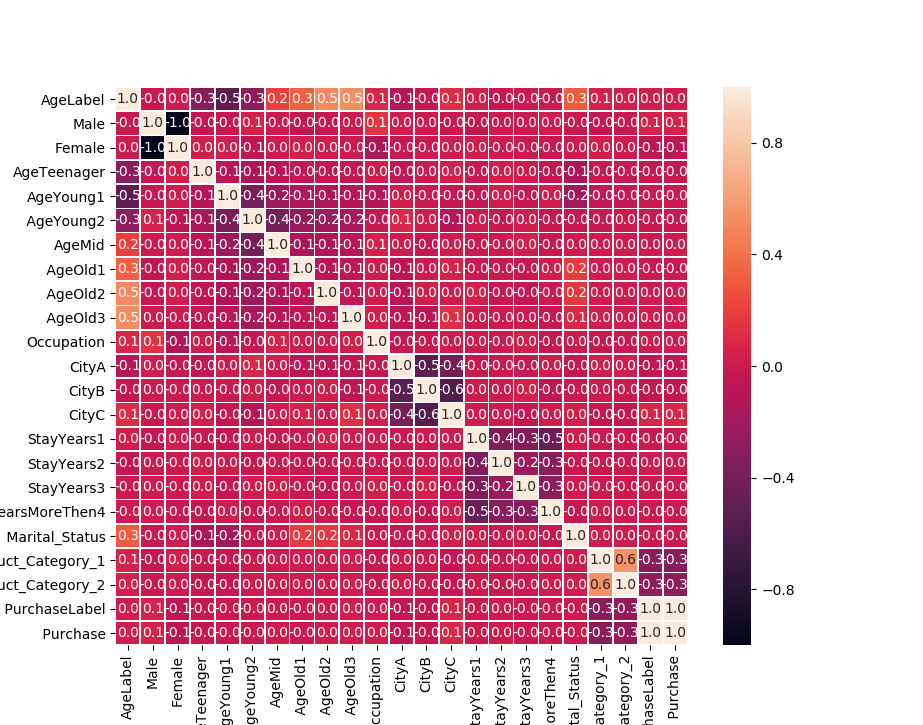
val featureCols4 = Array("Male","Female", "AgeTeenager", "AgeYoung1", "AgeYoung2","AgeMid", "AgeOld1", "AgeOld2", "AgeOld3","Occupation")
val label4="Marital_Status"
val mlUtil= new MLUtil()
//mlUtil.decisionTree(DF,featureCols1,label1)
mlUtil.decisionTree(DF,featureCols4,label4)marital_status的预测模型准确度:
accuracy fitting: 0.6191938808380212
没有评论