虽然 MLlib 已经足够简单易用,但是如果目标数据集结构复杂需要多次处理,或者是对新数据进行预测的时候需要结合多个已经训练好的单个模型进行综合预测,那么使用 MLlib 将会让程序结构复杂,难于理解和实现。
因此在 Spark 的生态系统里,出现一个可以用于构建复杂机器学习工作流应用的新库 ML Pipeline
原理:
先理解一下Spark ML中的相关概念:
DataFrame:ML API使用这个来自Spark SQL的概念作为ML dataset,可以保存多种数据类型。比如:使用不同的列存储文本、特征向量、真实标签和预测结果。
Transformer:这是个是指一个算法将一个DataFrame transform成另一个DataFrame。也就是训练好的模型。比如:一个ML模型就是一个Transformer能够将一个特征数据的DataFrame转成预测结果的DataFrame。
Estimator:是指一个操作DataFrame产生Transformer的算法。比如:一个学习算法就是一个Estimator,可以在一个DataFrame上训练得到一个模型。一个Estimator需要实现方法fit(),这个方法接收一个DataFrame并输出一个模型也就是Transformer
机器学习中,通常有一系列的算法活动在数据中处理和学习。比如:一个简单的数据文本处理流程大概分为下面几个阶段:
- 将文本分割成words
- 将words转化为数值型的特征向量
- 通过特征向量和标签学习得到一个预测模型
Pipeline 解决了什么问题?
Pipeline:一个Pipeline链定义了一连串的Stage,将多个Transformer和Estimator组合在一起组成一个ML workflow,让这些Stage按照顺序执行:
ParamMap:ParamMap是一个(parameter, value)的集合,通过ParamMap对fit()和transform()设置参数。MLLib就会自动完成这些参数的不同组合。Pipeline一次性完成了整个模型的参数调优,而不是独立对每个参数进行调优。
实践1–Pipeline模式:
一个简单的二元分类问题, 规则也比较简单, 就是带有spark字符的 字符串识别标签为1, 否则为0,使用逻辑回归
创建Spark任务:
val spark = SparkSession
.builder
.appName("PipelineML").master("local[2]")
.getOrCreate()创建训练集
因为只是简单的逻辑回归, 规则也比较简单, 就是带有spark字符的 字符串识别标签为1, 否则为0
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")定义Pipeline 工作流
有点像TensorFlow中定义一个 graph的过程, 感觉流程整体比较清晰一些
val tokenizer = new Tokenizer() //这是一个Transformer
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()//这是一个Transformer
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()//这是个Estimator
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))执行Pipeline工作流,生成模型
val model = pipeline.fit(training)保存&加载模型(可选)
try {
model.write.overwrite().save("/sparkProject/model/spark-logistic-regression-model")
pipeline.write.overwrite().save("sparkProject/model/unfit-lr-model")
val sameModel = PipelineModel.load("sparkProject/model/spark-logistic-regression-model")
}catch{
case ex: Exception =>println(ex)
case ex: Throwable =>println("found a unknown exception"+ ex)
}补充说明: 模型的加载类要和算法类对应起来,一般相关类都在这个Jar包中,可以在此找算法类对应的模型加载类:
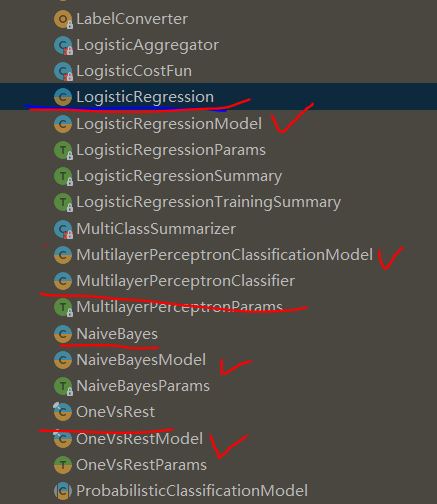
下面红线表示算法类,临近的打勾的类就是其模型加载时用的类
使用模型对测试数据做预测
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// Make predictions on test documents.
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}预测结果:
(4, spark i j k) –> prob=[0.15964077387874118,0.8403592261212589], prediction=1.0
(5, l m n) –> prob=[0.8378325685476612,0.16216743145233875], prediction=0.0
(6, spark hadoop spark) –> prob=[0.06926633132976273,0.9307336686702373], prediction=1.0
(7, apache hadoop) –> prob=[0.9821575333444208,0.01784246665557917], prediction=0.0
实践2–PipeLine+ ParamMap调参模式:
还是基于<spark 实践–随机森林&预测> 中金融风控的场景样例,使用ML PipeLine方式训练模型,并且自动调整参数, 看看会有什么差异?
之前的流程不重复介绍, 只从模型训练阶段开始介绍:
定义训练模型的算法并且训练处模型:
val classifier = new RandomForestClassifier().setImpurity("gini").setMaxDepth(3).setNumTrees(20).setFeatureSubsetStrategy("auto").setSeed(5043)
val model = classifier.fit(trainingData)
定义二元分类器:
val evaluator = new BinaryClassificationEvaluator().setLabelCol("label")
定义模型需要的参数的值的调试范围:
之前介绍过随机森林算法的几个关键参数:
- maxDepth:每棵树的最大深度。增加树的深度可以提高模型的效果,但是会延长训练时间。
- maxBins:连续特征离散化时选用的最大分桶个数,并且决定每个节点如何分裂。(这个不太懂一般使用默认值)
- impurity:计算信息增益的指标
- numTrees:设置的树的数目
val paramGrid = new ParamGridBuilder()
.addGrid(classifier.maxBins, Array(25, 31))
.addGrid(classifier.maxDepth, Array(5, 10))
.addGrid(classifier.numTrees, Array(20, 60))
.addGrid(classifier.impurity, Array("entropy", "gini"))
.build()
定义Pipeline workflow
这里的workflow就只有一个stage—随机森林生成模型的算法 classifier
val steps: Array[PipelineStage] = Array(classifier)
val pipeline = new Pipeline().setStages(steps)
使用模型选择器CrossValidator开始训练—–配置的模型的参数集合ParamMap,需要通过CrossValidator加载使用
Spark提供在org.apache.spark.ml.tuning包下提供了模型选择器,可以替换参数然后比较模型输出, CrossValidator就是其中一种;
Pipeline在参数网格paramGrid 上不断地爬行,自动完成了模型优化的过程:对于每个ParamMap类,CrossValidator训练得到一个Estimator,然后用Evaluator来评价结果,然后用最好的ParamMap和整个数据集来训练最优的Estimator
val cv = new CrossValidator() .setEstimator(pipeline) .setEvaluator(evaluator) .setEstimatorParamMaps(paramGrid) .setNumFolds(10)//表示数据集分成10份,9份为training,1份为validation val pipelineFittedModel = cv.fit(trainingData)
使用模型对测试集做预测
val predictions2 = pipelineFittedModel.transform(testData)
val accuracy2 = evaluator.evaluate(predictions2)//通过二元分类器evaluator对比Label结果和预期的差异
println("accuracy after pipeline fitting" + accuracy2)
最终准确率打印:
accuracy after pipeline fitting 0.7296862429605789
Pipeline+ 调参模式 下训练的模型精准度结果好像比非Pipeline+ 调参的 结果0.7178197908286402 (<spark 实践–随机森林&预测>文档中的结果) 要好一点
没有评论