Spark任务怎么提交到worker集群执行?
Spark 应用程序从编写到提交、执行、输出的整个过程如下图所示,图中描述的步骤如下:
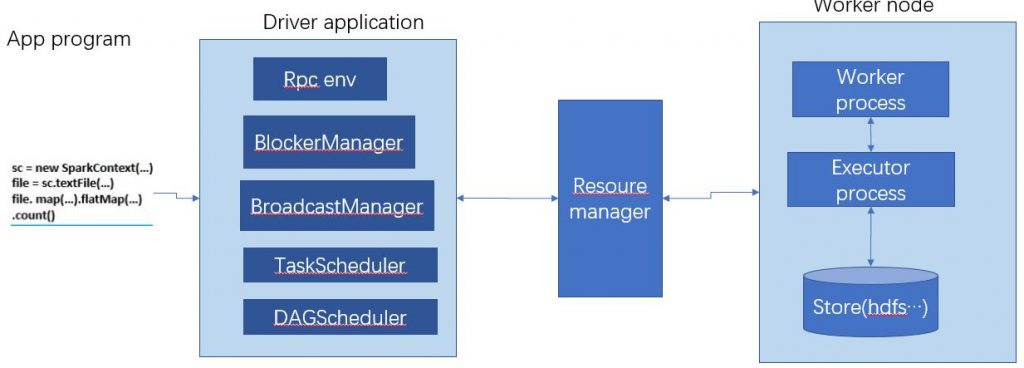
1) 用户使用SparkContext提供的API(常用的有textFile、sequenceFile、runJob、stop等)编写Driver application程序。程序先离线被打成Jar包存储起来等待被加载执行,存储的位置有3种:
- file: – 绝对路径 file:/ dirver的http file server。executors会从该driver上拉取jar。
- hdfs:, http:, https:, ftp: -从这些位置拉取
- local: – 从worke所在 每台机器本地拉取文件,适合于jar包很大的场景。
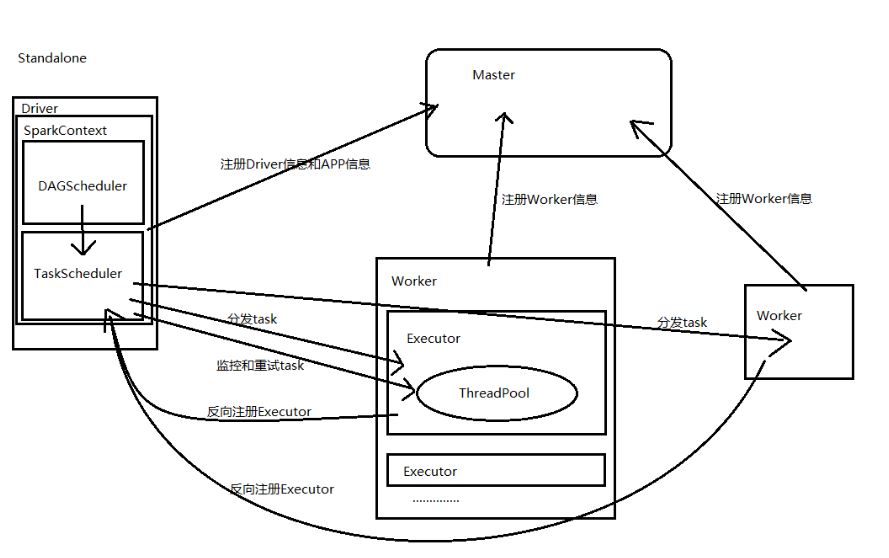
2) Spark 客户端提交SparkSubmit 指令,会创建一个ClientEndpoint对象,该对象负责与Master通信交互,ClientEndpoint向Master发送一个RequestSubmitDriver消息,表示提交用户程序
standalone clusters 部署模式中有2中启动模式:
- client模式: Driver 与客户端程序在同一个进程中,被客户端进程启动(个人理解就是sparkContext初始化过程在spark client端)
- cluster模式:Driver 是在worker集群中的某个worker 进程中被启动(sparkcontext初始化在某个worker上完成),下图是cluster模式下Driver的部署示意图:
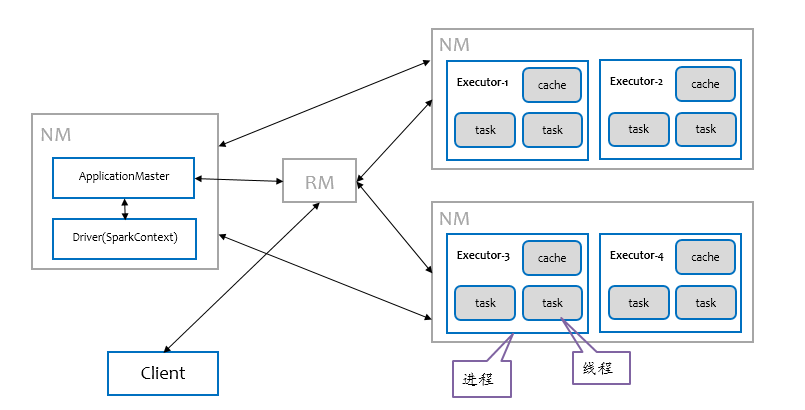
可以使用spark shell 和代码方式调用SparkSubmit 2种方式触发;而且通过 Spark submit方式启动App 应用, app的 jar包会被自动分发到所有的 worker nodes上
SparkSubmit 详细参数参考 https://spark.apache.org/docs/latest/submitting-applications.html
上述2种方式本质上都是启动以SparkSubmit为主类的jvm进程完成SparkContext的初始化;
最终使用SparkConf和SparkContext来初始化用户提交的app program(Jar包):
- 首先会使用BlockManager和BroadcastManager将任务的Hadoop配置进行广播。
- 然后由DAGScheduler将任务转换为RDD并组织成DAG,DAG还将被划分为不同的Stage。
- 最后由TaskScheduler借助ActorSystem将Task任务提交给集群管理器(Cluster/resource Manager)。
3) 集群管理器(Cluster Manager)收到submit请求后(RequestSubmitDriver消息),注册相关driver到driver 队列,然后根据该driver所需资源分配worker,调用worker RpcEndPointRef向Worker发送LaunchDriver消息,告诉worker启动该driver,driver会创建SparkContext对象
4) worker创建好Executor后,Executor将信息发送给Driver
5) SparkContext的 TaskScheduler将Task任务发送给指定Executor,进行任务计算
6) 将Task计算结果返回Driver,Spark任务计算完毕,一系列处理关闭Spark任务。
主要的流程如下所示:
没有评论