1.DB服务常见问题
1、慢SQL,查询语句不好,没有优化,如:没有索引或者没有用到索引等
2、I/O吞吐量小,形成了瓶颈效应。
3、内存不足
4、 网络速度慢
5、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
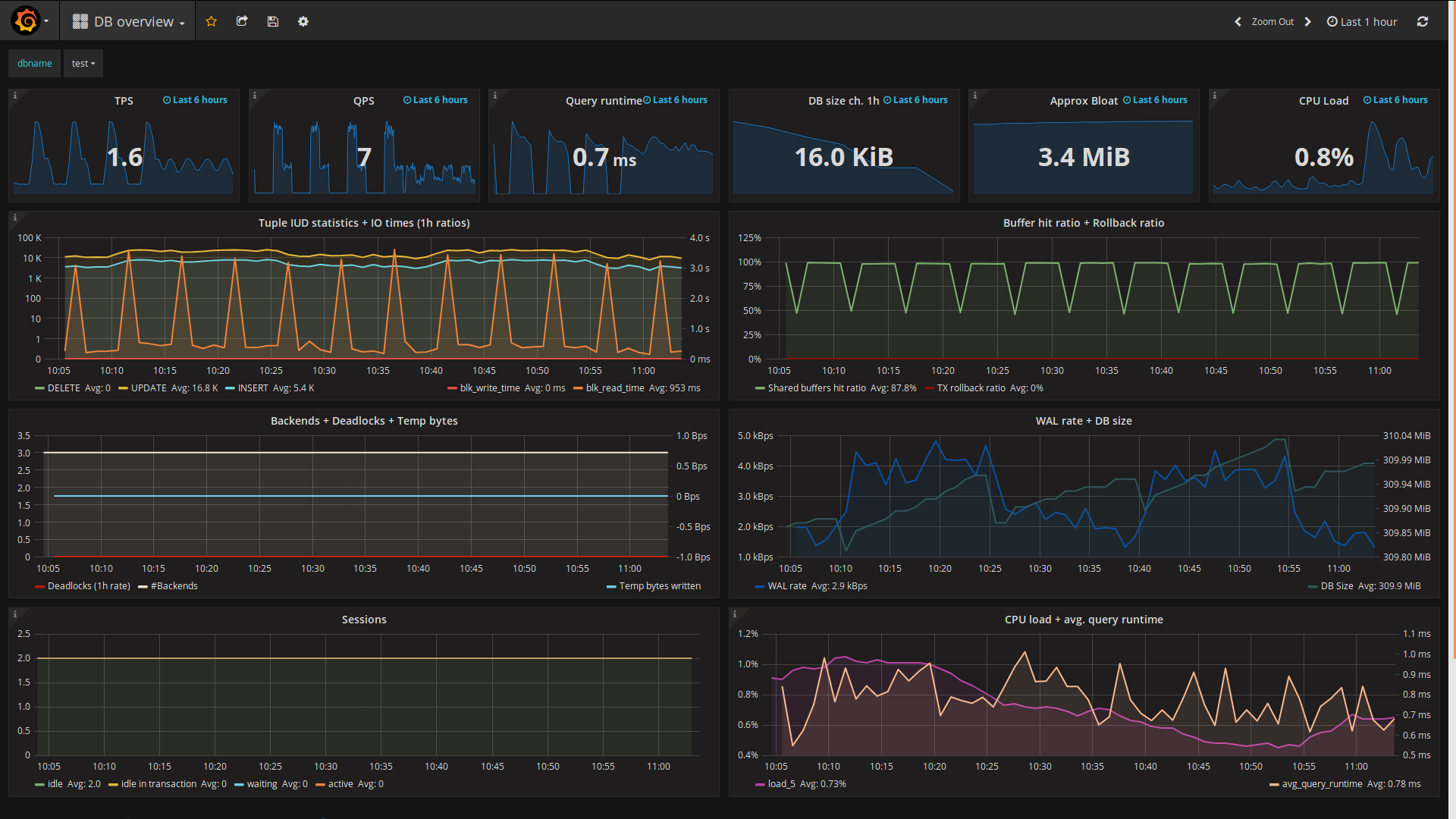
2. DB监控指标&工具:
- 资源层:和其他软件一样
- 业务层:
- 数据库可连接性
- 监控数据库的连接数 :导致数据库的连接数突然增长可能是出现阻塞(数据库并发请求突增),或像redis这样的缓存失效(可以通过redis命中率监控观察)
- 数据库吞吐量监控:TPS ,QPS
- 数据库占用磁盘空间大小(数据大小 + 索引大小)
- 磁盘IO
- 死锁情况:
- 慢SQL统计:
Postgres为例,选择满足如上多纬度实时监控需求的工具—pgwatch2(只支持linux环境的PG监控,Windows上的PG资源监控可以用zabbix+业务层监控pgadmin) :
3. DB服务问题定位流程:
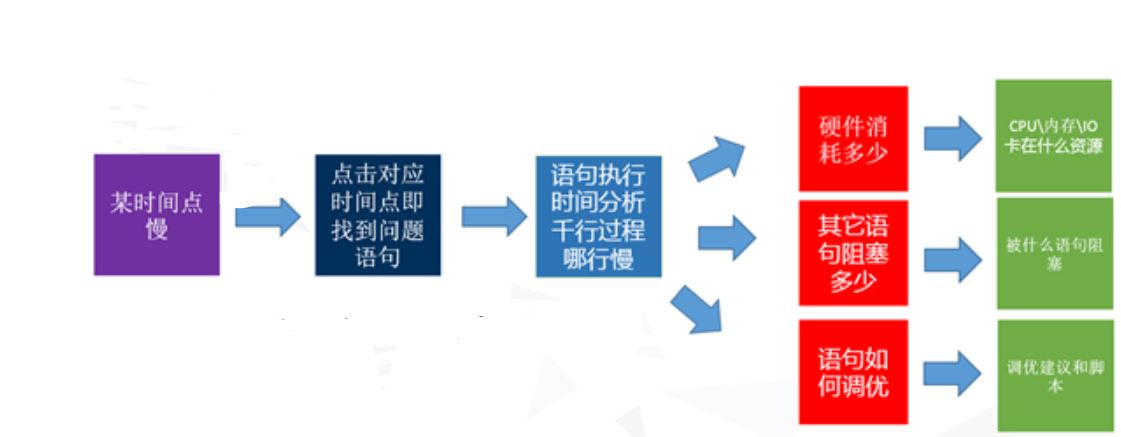
3.1 观察慢SQL监控统计,某个时间点运行语句非常慢
3.2 如果这个语句平时也不慢,拿下来一执行几毫秒就完成了。很可能是语句执行的时候被阻塞了
阻塞有两种:硬件的资源等待,或语句资源争用的锁(也是我们常说的锁表/死锁/阻塞)
那我们就会清楚地知道当时是为什么慢? 卡在硬件还是软件的语句上?
如果这个SQL平时也慢,可以直接用EXPLAIN 分析原因;
3.3 通过资源监控查看CPU、内存、IO是否出现瓶颈? 是否有deadlock 出现?
3.4 一般慢SQL会同时出现CPU占用率升高等特征,再通过 EXPLAIN 分析较低效SQL的执行计划分析具体SQL有哪些问题(如果SQL语句无法再优化,可能就需要调整系统资源…)
一般对于测试人员,不要求能完全定位出所有问题根因,能初步定位一些SQL类的常见问题
4. 慢SQL 性能优化原则
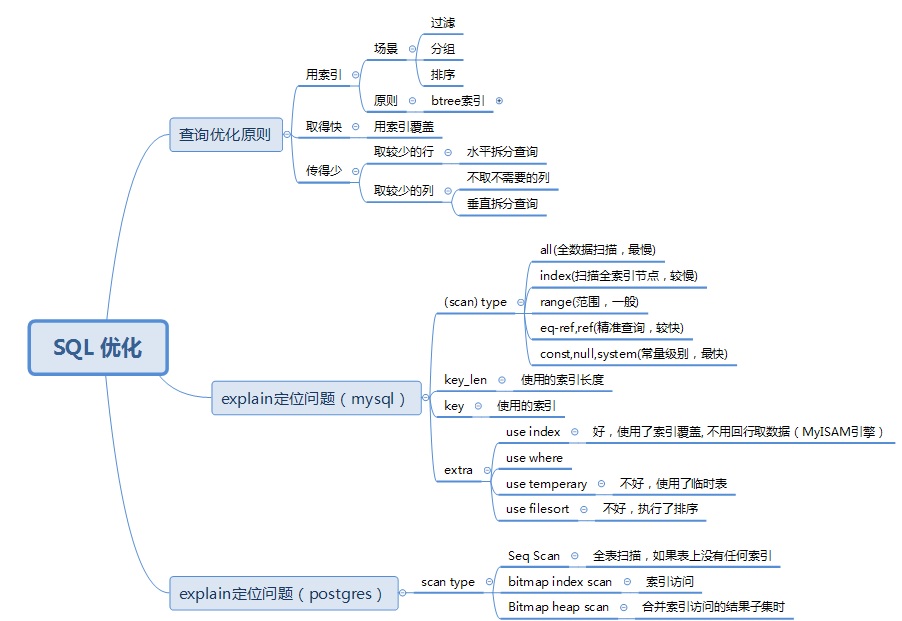
btree索引使用原则:

5. 定位慢SQL常用查询语句(postgres)
PostgreSQL提供了pg_stat_statements来存储SQL的运行次数,总运行时间,shared_buffer命中次数,shared_buffer read次数等统计信息
一个数据库中SQL调用频率Top10排序 select s.* from pg_stat_statements s join pg_database d on d.oid = s.dbid and d.datname = current_database() ORDER BY mean_time DESC limit 10 一段时间内的总耗时Top10 select s.* from pg_stat_statements s join pg_database d on d.oid = s.dbid and d.datname = current_database() ORDER BY total_time DESC limit 10 单次最耗时(慢查询) Top10 SELECT query, calls, total_time, (total_time/calls) as average ,rows FROM pg_stat_statements WHERE rows > 0 ORDER BY average DESC LIMIT 10; 单次调用最耗IO SQL TOP 10 select userid,dbid,query,calls,total_time from pg_stat_statements order by (blk_read_time+blk_write_time)/calls desc limit 10; 总最耗IO SQL TOP 10 select userid, dbid, query from pg_stat_statements order by (blk_read_time+blk_write_time) desc limit 10; 单次最耗时(慢查询)SQL Top10 & DB缓存命中情况 SELECT query, calls, total_time, (total_time/calls) as average ,rows, 100.0 * shared_blks_hit /nullif(shared_blks_hit + shared_blks_read, 0) AS hit_percent FROM pg_stat_statements WHERE rows > 0 ORDER BY average DESC LIMIT 10;
6.慢SQL几个案例:
6.1 Postgres –无索引,一次查询大量数据
1.1 现象
添加XX事件后,YY事件和ZZ事件界面全都加载不出来,提示网关超时
1.2 排查
a. 打开pg的pg_stat_statements后,重新点击业主人员页面
b. 通过查询pg_stat_statements视图得到慢查询的SQL列表(同时监控PG服务的CPU占用率飙高)
SELECT query, calls, total_time, (total_time/calls) as average ,rows FROM pg_stat_statements WHERE rows > 0 ORDER BY average DESC LIMIT 10;
发现几个SQL耗时非常长,需要80+s、60+s、62s返回,其中一个如下:
使用explain分析SQL 执行计划:
EXPLAIN select count(?) from event e inner join XXX_A dc on dc.uuid = e.uuid left join YYY o on o.uuid = dc.org_uuid where ? = ? AND (o.uuid = $1 OR o.path like concat(?, $2,?)) CTE Scan on t (cost=1083521.50..1107521.50 rows=1200000 width=298) (actual time=19756.973..44323.061 rows=1200000 loops=1) Aggregate (cost=2756804.06..2756804.07 rows=1 width=8) -> Hash Join (cost=6393.00..2666798.62 rows=36002174 width=0) Hash Cond: ((e.resource_uuid)::text = (dc.uuid)::text) -> Append (cost=0.00..1601669.73 rows=36002174 width=33) -> Seq Scan on event e (cost=0.00..0.00 rows=1 width=82) -> Seq Scan on event_201805 e_1 (cost=0.00..10.40 rows=40 width=33) -> Seq Scan on event_201806 e_2 (cost=0.00..10.20 rows=20 width=82) -> Seq Scan on event_201807 e_3 (cost=0.00..10.20 rows=20 width=82) -> Seq Scan on event_201808 e_4 (cost=0.00..10.20 rows=20 width=82) -> Seq Scan on event_201809 e_5 (cost=0.00..10.20 rows=20 width=82) -> Seq Scan on event_201810 e_6 (cost=0.00..10.20 rows=20 width=82) -> Seq Scan on event_20180403 e_7 (cost=0.00..266965.04 rows=6001004 width=33) -> Seq Scan on event_20180402 e_8 (cost=0.00..266963.04 rows=6001004 width=33) -> Seq Scan on event_20180401 e_9 (cost=0.00..266918.14 rows=6000014 width=33) -> Seq Scan on event_20180404 e_10 (cost=0.00..266921.82 rows=5999982 width=33) -> Seq Scan on event_20180405 e_11 (cost=0.00..266920.16 rows=6000016 width=33) -> Seq Scan on event_20180406 e_12 (cost=0.00..266920.13 rows=6000013 width=33) -> Hash (cost=3971.00..3971.00 rows=100000 width=66) -> Seq Scan on XXX_A dc (cost=0.00..3971.00 rows=100000 width=66)
问题分析:有6张600W的表 使用的是Seq Scan 全表扫描…,没有索引
6.2 mysql –锁表
现象:在XX平台 并发用户查询 YY 信息,Z min后速度将会越来越慢,需要>10s
存储过程循环30次更新操作
/*30次更新操作*/
BEGIN DECLARE v1 INT DEFAULT 30;
WHILE v1 > 0 DO
update jx_attach set complete=1,attach_size=63100 where cycore_file_id='56677142da502cd8907eb58f';
SET v1 = v1 - 1;
END WHILE;
END
时间: 29.876s
执行结果(持续一段时间后速度越来越慢,出现等待锁)
# Time: 151208 22:41:24 # User@Host: zmduan[zmduan] @ [192.168.235.1] Id: 2 # Query_time: 1.848644 Lock_time: 0.780778 Rows_sent: 0 Rows_examined: 393382 SET timestamp=1449643284; update jx_attach set complete=1,attach_size=63100 where cycore_file_id='56677142da502cd8907eb58f'; ......... ........ # User@Host: zmduan[zmduan] @ [192.168.235.1] Id: 2 # Query_time: 2.868598 Lock_time: 1.558542 Rows_sent: 0 Rows_examined: 393382 SET timestamp=1449643805; update jx_attach set complete=1,attach_size=63100 where cycore_file_id='56677142da502cd8907eb58f'; [root@localhost log]# tail -f slow_query.log # User@Host: zmduan[zmduan] @ [192.168.235.1] Id: 19 # Query_time: 1.356797 Lock_time: 0.000169 Rows_sent: 1 Rows_examined: 393383 SET timestamp=1449643805; SELECT * FROM jx_attach ja,jx_feed jf where ja.feed_id=jf.feed_id and ja.cycore_file_id='56677146da502cd8907eb5b7'; # User@Host: zmduan[zmduan] @ [192.168.235.1] Id: 2 # Query_time: 2.868598 Lock_time: 1.558542 Rows_sent: 0 Rows_examined: 393382 SET timestamp=1449643805; update jx_attach set complete=1,attach_size=63100 where cycore_file_id='56677142da502cd8907eb58f';
也可以通过使用命令查看是否有连接上的进程状态:
show processlist;
下图显示有一个连接上有锁表:

分析:
CREATE TABLE `jx_attach` ( `attach_id` int(11) NOT NULL AUTO_INCREMENT, `feed_id` int(11) DEFAULT NULL , `attach_name` varchar(255) NOT NULL, `cycore_file_id` varchar(255) DEFAULT NULL , `attach_size` bigint(20) NOT NULL DEFAULT '0', `complete` smallint(6) NOT NULL DEFAULT '0' , PRIMARY KEY (`attach_id`), KEY `jx_trend_attach_FK` (`feed_id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=394160 DEFAULT CHARSET=utf8;
使用innodb存储引擎,支持行级锁:innodb的行锁是通过给索引项加锁实现的,只有通过索引条件检索数据时,innodb才使用行锁,否则使用表锁。
根据当前的数据更新语句:
update jx_attach set complete=1,attach_size=63100 where cycore_file_id=’56677142da502cd8907eb58f’;
该条件字段cycore_file_id并没有添加索引,所以导致数据表被锁
解决方案:为cycore_file_id添加索引,改表级索引为行级索引
最终效果:(30次更新操作)时间: 0.094s ,比原值29.876s 提升了几个数量级
没有评论