项目目标:
对家用电器电量消耗数据做分析和多种模型的预测
a. 实时提取部分特征用于预测家用用电和季节的关系
b.提取部分特征用于聚类分析—根据用电量特征做聚类
c. 还可以使用Spark离线机器学习做复杂的预测
数据集(离线)分析:
household_power_consumption数据维度信息:
1.date: 日期,格式为 dd/mm/yyyy
2.time: 时间特征,格式 hh:mm:ss
3.global_active_power: household global minute-averaged active power (in kilowatt) 平均每分钟的家用active 状态的电力值(单位是千瓦)
4.global_reactive_power: household global minute-averaged reactive power (in kilowatt) 平均每分钟的家用reactive 状态的电力值(单位是千瓦)
5.voltage: minute-averaged voltage (in volt) 平均每分钟的电压值
6.global_intensity: household global minute-averaged current intensity (in ampere) 平均每分钟的家用电流强度值(单位是安培)
7.sub_metering_1: (in watt-hour of active energy). kitchen, containing mainly a dishwasher, an oven and a microwave (hot plates are not electric but gas powered). 厨房电器的用电量
8.sub_metering_2:(in watt-hour of active energy). laundry room, containing a washing-machine, a tumble-drier, a refrigerator and a light. 洗衣房电器的用电量
9.sub_metering_3:(in watt-hour of active energy). electric water-heater and an air-conditioner 热水器,空调的用电量
Date;Time;Global_active_power;Global_reactive_power;Voltage;Global_intensity;Sub_metering_1;Sub_metering_2;Sub_metering_3
16/12/2006;17:24:00;4.216;0.418;234.840;18.400;0.000;1.000;17.000
16/12/2006;17:25:00;5.360;0.436;233.630;23.000;0.000;1.000;16.000
16/12/2006;17:26:00;5.374;0.498;233.290;23.000;0.000;2.000;17.000数值型特征分析:
原来以为Global_active_power;Global_reactive_power;Voltage;Global_intensity;Sub_metering_1;Sub_metering_2;Sub_metering_3 几列都可能是数值型,看分析结果,并不是这样, 只有Sub_metering_3目前的数据全是Float型…部分数据存在类型不统一的异常值!
Sub_metering_3
count 2.049280e+06
mean 6.458447e+00
std 8.437154e+00
min 0.000000e+00
25% 0.000000e+00
50% 1.000000e+00
75% 1.700000e+01
max 3.100000e+01非数值型分布分析:
print(df.describe(include=[‘O’]))
Date Time ... Sub_metering_1 Sub_metering_2
count 2075250 2075250 ... 2075250 2075250
unique 1442 1440 ... 89 82
top 24/12/2006 20:22:00 ... 0.000 0.000
freq 1440 1442 ... 1880175 1436830特征数据类型分析:
再次证明数据种除了Sub_metering_3 之外,都存在混合类型的异常值
RangeIndex: 2075250 entries, 0 to 2075249
Data columns (total 9 columns):
Date object
Time object
Global_active_power object
Global_reactive_power object
Voltage object
Global_intensity object
Sub_metering_1 object
Sub_metering_2 object
Sub_metering_3 float64
dtypes: float64(1), object(8)异常值分析
如何找到异常值? 个人使用类似相关性分析脚本,设置其他列与Sub_metering_3的相关性分析
print(df[['Global_active_power', 'Sub_metering_3']].groupby(['Global_active_power'], as_index=False).mean().sort_values(by='Sub_metering_3', ascending=False))
比如看到Global_active_power存在为“?”的字符,而一般此时的Sub_metering_3为NaN
4168 9.606 0.000000
3998 8.246 0.000000
4069 8.592 0.000000
4006 8.274 0.000000
3375 6.812 0.000000
4186 ? NaN其他列类似操作,发现都是出现? 号异常值和NaN异常值比较多(用于flink实时流处理数据时参考需要)
104 225.950 0.000000
2753 252.480 0.000000
2836 254.150 0.000000
2837 ? NaNsut_meterting_3列有少量空值情况,比例较少,可以考虑直接剔除;
Total Percent
Date 0 0.000000
Time 0 0.000000
Global_active_power 0 0.000000
Global_reactive_power 0 0.000000
Voltage 0 0.000000
Global_intensity 0 0.000000
Sub_metering_1 0 0.000000
Sub_metering_2 0 0.000000
Sub_metering_3 25979 0.012518特征相关性分析:
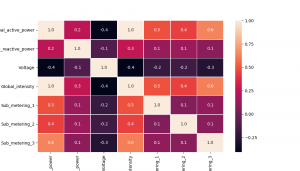
所有数值型数据维度之间的相关性:
Global_active_power 和Global_intensity 基本是非常强相关为1.0, 机器学习建模时,这两个特征可以删掉其中一个
Voltage 和大部分特征都 负相关
month VS Global_active_power, hour VS Global_active_power相关性:
df["month"] = df['Date'].map(lambda x: x.split('/')[1])
print(df[['month', 'Global_active_power']].groupby(['month'], as_index=False).mean().sort_values(by='Global_active_power', ascending=False))结果显示冬季11-3约的用电量较高
month Global_active_power
3 12 1.489729
0 1 1.462226
2 11 1.318757
4 2 1.300431
5 3 1.231343
1 10 1.128386
6 4 1.047146
7 5 1.029571
11 9 0.981280
8 6 0.909148
9 7 0.700359
10 8 0.548587df["hour"] = df['Time'].map(lambda x: x.split(':')[0])
print(df[['hour', 'Global_active_power']].groupby(['hour'], as_index=False).mean().sort_values(by='Global_active_power', ascending=False))结果显示时间点和用电量关系比较大, 一般用电高分分布在晚上7pm-22pm, 早上7am-10am, 00am-06am是用电低峰
hour Global_active_power
20 20 1.901192
21 21 1.880670
19 19 1.739385
7 07 1.483839
8 08 1.459619
22 22 1.422973
9 09 1.332947
18 18 1.321225
10 10 1.268536
11 11 1.244401
12 12 1.205533
13 13 1.145469
14 14 1.082330
17 17 1.058686
15 15 0.988936
16 16 0.949170
23 23 0.908003
6 06 0.794893
0 00 0.661046
1 01 0.540794
2 02 0.477152
5 05 0.453438
3 03 0.443682
4 04 0.443305同理month VS Voltage , hour VS Voltage 相关性:
仍然是冬季Voltage相对较高; 但时间点上,反而是凌晨Voltage较高;
month Voltage
3 12 242.749065
0 1 242.177646
5 3 241.528648
4 2 241.459366
2 11 241.134285
6 4 241.044744
1 10 240.316443
11 9 240.231707
10 8 240.061417
9 7 240.003656
8 6 239.912401
7 5 239.008514
hour Voltage
23 23 242.946606
3 03 242.657551
2 02 242.587233
4 04 242.375368
0 00 242.348849
5 05 242.036669
15 15 242.018662
6 06 241.900241
16 16 241.757934
1 01 241.680677
14 14 241.485995
22 22 240.886302
13 13 240.678314
17 17 240.269351
12 12 240.126100
7 07 239.885990
8 08 239.462342
11 11 239.388296
9 09 239.367427
18 18 239.286458
10 10 239.278824
21 21 239.071192
20 20 239.036712
19 19 238.655403同理month VS Sub_metering_1, hour VS Sub_metering_1( 厨房电器)相关性:
季节对于Sub_metering_1 的用电量影响不大,比较均衡,合理;
时间上,早,中,晚饭时间用电量较高,比较合理;
month Sub_metering_1
0 1 1.406481
8 6 1.330837
3 12 1.311991
2 11 1.306718
5 3 1.266721
7 5 1.234916
11 9 1.210070
4 2 1.132143
6 4 1.075624
1 10 1.060990
9 7 0.707637
10 8 0.487054
hour Sub_metering_1
21 21 2.812301
20 20 2.778697
19 19 2.653954
22 22 2.271091
12 12 1.542238
9 09 1.500025
11 11 1.489728
14 14 1.463379
15 15 1.459986
8 08 1.407922
18 18 1.259636
13 13 1.245665
10 10 1.134093
23 23 0.988710
16 16 0.971822
17 17 0.734044
0 00 0.383752
7 07 0.320170
1 01 0.266354
2 02 0.156038
3 03 0.066523
4 04 0.043836
6 06 0.035152
5 05 0.027251同理month VS Sub_metering_2, hour VS Sub_metering_2(洗衣房电器)相关性:
可以看出似乎冬季的Sub_metering_2 的用电量比较高,夏季比较少;
时间点上大部分用电时间点在下午和晚上;
month Sub_metering_2
5 3 1.661699
0 1 1.548839
1 10 1.530327
3 12 1.441189
2 11 1.412368
4 2 1.386569
7 5 1.307813
11 9 1.280998
8 6 1.244410
6 4 1.173244
9 7 0.992232
10 8 0.782521
hour Sub_metering_2
14 14 2.555711
13 13 2.485943
19 19 2.099969
15 15 2.098161
12 12 2.045240
11 11 1.992813
17 17 1.959406
20 20 1.947948
16 16 1.898202
21 21 1.848688
18 18 1.796948
10 10 1.529939
22 22 1.212847
9 09 1.053148
8 08 0.983629
23 23 0.851175
0 00 0.552765
7 07 0.497944
1 01 0.389206
3 03 0.346190
2 02 0.339761
4 04 0.328333
6 06 0.327293
5 05 0.314384同理month VS Sub_metering_3, hour VS Sub_metering_3(热水器,空调)相关性:
季节上看冬季和初春,Sub_metering_3类型电器用电较多;
时间点上看用电低峰在凌晨,在早上07点开始一直到下午,高峰聚集在09-10点
month Sub_metering_3
3 12 7.807011
0 1 7.794054
4 2 7.587332
2 11 7.067275
5 3 6.928493
7 5 6.696841
6 4 6.678212
1 10 6.420007
11 9 6.228666
8 6 6.172105
9 7 4.275768
10 8 3.640474
hour Sub_metering_3
9 09 12.496378
8 08 12.491658
10 10 11.554009
7 07 10.514781
11 11 10.204382
12 12 9.119202
20 20 8.466858
13 13 8.330243
21 21 7.622840
14 14 7.289591
19 19 6.796036
15 15 6.135814
22 22 5.745389
18 18 5.744447
16 16 5.402105
17 17 5.324743
6 06 4.164537
23 23 4.082671
0 00 3.015655
1 01 2.372564
5 05 2.106158
2 02 1.967618
4 04 1.828841
3 03 1.661874
Flink实现实时特征处理:
经过上述的离线数据分析后,得出一些数据特征处理的规则:
- 处理有异常值’?’的event
- 处理有空值特征的event
- Date特征需要提取抽象出新的季节特征列,并做哑变量化处理
- Time特征需要提取抽象出新的时间段特征列,并作哑变量化处理
- 如果出现新的异常特征值,有提示机制(方便更新特征处理规则)
- 定义各种Sink输出到外部服务, 用于一些批处理服务(ML等)
- 是否需要flink实时ML预测?
定义数据源
public static class PowerSource implements SourceFunction<myqPower> {
private final String dataFilePath;
private final int servingSpeed;
private transient BufferedReader reader;
private transient InputStream FStream;
public PowerSource(String dataFilePath) {
this(dataFilePath, 1);
}
public PowerSource(String dataFilePath, int servingSpeedFactor) {
this.dataFilePath = dataFilePath;
this.servingSpeed = servingSpeedFactor;
}
@Override
public void run(SourceContext<myqPower> sourceContext) throws Exception {
FStream = new FileInputStream(dataFilePath);
reader = new BufferedReader(new InputStreamReader(FStream, "UTF-8"));
String line;
long time;
while (reader.ready() && (line = reader.readLine()) != null) {
myqPower power = myqPower.instanceFromString(line);
if (power == null){
continue;//出现异常--列个数错误<部分列出现空值>的数据返回null, 不处理该event,继续处理后续event
}
time = getEventTime(power);
sourceContext.collectWithTimestamp(power, time);
sourceContext.emitWatermark(new Watermark(time - 1));
}
this.reader.close();
this.reader = null;
this.FStream.close();
this.FStream= null;
}
public long getEventTime(myqPower power) {
return power.getEventTime();
}
@Override
public void cancel() {
try {
if (this.reader != null) {
this.reader.close();
}
if (this.FStream!= null) {
this.FStream.close();
}
} catch (IOException ioe) {
throw new RuntimeException("Could not cancel SourceFunction", ioe);
} finally {
this.reader = null;
this.FStream= null;
}
}
}myqPower数据结构类定义:
public class myqPower implements Serializable {
public String Date;
public String Time;
public float Global_active_power;
public float Global_reactive_power;
public float Voltage;
public float Global_intensity;
public float Sub_metering_1;
public float Sub_metering_2;
public float Sub_metering_3;
public DateTime eventTime;
public myqPower() {
this.eventTime = new DateTime();
}
public myqPower(String Date, String Time, float Global_active_power, float Global_reactive_power,
float Voltage, float Global_intensity, float Sub_metering_1, float Sub_metering_2,
float Sub_metering_3) {
this.eventTime = new DateTime();
this.Date = Date;
this.Time = Time;
this.Global_active_power = Global_active_power;
this.Global_reactive_power = Global_reactive_power;
this.Voltage = Voltage;
this.Global_intensity = Global_intensity;
this.Sub_metering_1 = Sub_metering_1;
this.Sub_metering_2 = Sub_metering_2;
this.Sub_metering_3 = Sub_metering_3;
}
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(Date).append(",");
sb.append(Time).append(",");
sb.append(Global_active_power).append(",");
sb.append(Global_reactive_power).append(",");
sb.append(Voltage).append(",");
sb.append(Global_intensity).append(",");
sb.append(Sub_metering_1).append(",");
sb.append(Sub_metering_2).append(",");
sb.append(Sub_metering_3).append(",");
return sb.toString();
}
public static myqPower instanceFromString(String line) {
String[] tokens = line.split(";");
if (tokens.length != 9) {
System.out.println("#############Invalid record: " + line+"\n");//异常提示,可以改成Log形式,这里方便调试暂时用Stdout
return null;
//throw new RuntimeException("Invalid record: " + line);
}
myqPower power = new myqPower();
try {
power.Date = tokens[0];
power.Time = tokens[1];
power.Global_active_power = tokens[2].length() > 0 ? Float.parseFloat(tokens[2]) : 0.0f;
power.Global_reactive_power = tokens[3].length() > 0 ? Float.parseFloat(tokens[3]) : 0.0f;
power.Voltage = tokens[4].length() > 0 ? Float.parseFloat(tokens[4]) : 0.0f;
power.Global_intensity = tokens[5].length() > 0 ? Float.parseFloat(tokens[5]) : 0.0f;
power.Sub_metering_1 =Float.parseFloat(tokens[6]);
power.Sub_metering_2 = Float.parseFloat(tokens[7]);
power.Sub_metering_3 = Float.parseFloat(tokens[8]);
} catch (NumberFormatException nfe) {
throw new RuntimeException("Invalid record: " + line, nfe);
}
return power;
}
public long getEventTime() {
return this.eventTime.getMillis();
}
}
- 异常值处理函数定义:
过滤掉空值,带有”?”号异常字符,Time,Date不满足格式要求的Event
public static class NoneFilter implements FilterFunction<myqPower> {
@Override
public boolean filter(myqPower power) throws Exception {
return DateIsNone(power.Date) && TimeIsNone(power.Time) && power.Global_active_power!='?'&& power.Voltage!='?'
&& power.Global_intensity!='?'&& power.Sub_metering_1!='?'&& power.Sub_metering_2!='?'&& power.Sub_metering_3!='?' ;
}
public boolean DateIsNone(String Date){
String[] arr = Date.split("/");
if (arr.length==3)
return true;
else
return false;
}
public boolean TimeIsNone(String Time){
String[] arr = Time.split(":");
if (arr.length==3)
return true;
else
return false;
}
}
- 数值化处理定义函数
不同的算法模型需要不同的特征,因此可以根据需要定义不同的FlatMap函数
比如预测类算法:
Date特征需要提取抽象出新的季节特征列,并做哑变量化处理,转换成春,夏,秋,冬4个季节;
Time特征需要提取抽象出新的时间段特征列,并作哑变量化处理,需要转换成 早晨,上午,中午,下午,晚上,凌晨几个阶段;
public static class powerFlatMap implements FlatMapFunction<myqPower, Tuple2<String,String>> {
@Override
public void flatMap(myqPower myqPower, Collector<Tuple2<String,String>> collector) throws Exception {
myqPower power = myqPower;
myqPowerWashed powerWashed=new myqPowerWashed();
int month = Integer.parseInt(myqPower.Date.split("/")[1]);
if(month >12){
throw new RuntimeException("!!!!!!!!!!!!!!!!!!!!!!get month >12:"+ month);
}
else if(month >=11 || month<=2){
powerWashed.winter=1;
}else if(month>=2 && month<=4){
powerWashed.Spring =1;
}else if(month>4 && month <8){
powerWashed.summer=1;
}else{
powerWashed.autumn=1;
}
int hour = Integer.parseInt(myqPower.Time.split(":")[0]);
if (hour >=7 && hour<12){
powerWashed.morning=1;
}else if(hour>=12 && hour<=14){
powerWashed.noon =1;
}else if(hour>14 && hour <18){
powerWashed.afternoon=1;
}else if(hour>=18 && hour <=23){
powerWashed.evening=1;
}else{
powerWashed.beforeDawn=1;
}
powerWashed.Global_active_power=myqPower.Global_active_power;
powerWashed.Global_reactive_power=myqPower.Global_reactive_power;
powerWashed.Sub_metering_1=myqPower.Sub_metering_1;
powerWashed.Sub_metering_2=myqPower.Sub_metering_2;
powerWashed.Sub_metering_3=myqPower.Sub_metering_3;
powerWashed.Voltage=myqPower.Voltage;
powerWashed.Global_intensity=myqPower.Global_intensity;
collector.collect(new Tuple2<>(myqPower.Date,powerWashed.toString()));
}
}比如聚类算法:
不同的spark 版本的kmeans算法的数据格式要求都不一样(伤脑筋…),比如mlib 库中的kmeans算法需要的格式比较简单就是特征之间用逗号隔开即可,因此定义的flatMap函数如下:
flink 特征处理增加一个flatmap函数用于生成 Spark Mlib 库的Kmeans类的格式:
特征使用了几个相关性较大的: 月份,时间点(小时),Global_active_power,Global_reactive_power,Voltage,Sub_metering_3
public static class powerFlatMapForKmeansMLib implements FlatMapFunction<myqPower, String> {
@Override
public void flatMap(myqPower myqPower, Collector<String> collector) throws Exception {
myqPower power = myqPower;
String month = myqPower.Date.split("/")[1];
String hour = myqPower.Time.split(":")[0];
StringBuilder sb = new StringBuilder();
sb.append(month).append(",");
sb.append(myqPower.Global_active_power).append(",");
sb.append(myqPower.Global_reactive_power).append(",");
sb.append(myqPower.Voltage).append(",");
sb.append(myqPower.Sub_metering_3);
collector.collect(sb.toString());
}
}
定义Flink Operation chain:
把不同的转换格式结果保存到不同的流式文件中,分别用于不同的算法处理
public static void main(String[] args) throws Exception {
ParameterTool params = ParameterTool.fromArgs(args);
final String input = "D:/code/dataML/household_power_consumption.txt";
final int servingSpeedFactor = 6000; // events of 10 minutes are served in 1 second
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// operate in Event-time
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// start the data generator
DataStream<myqPower> power = env.addSource(
new PowerSource(input, servingSpeedFactor));
DataStream<myqPower> modDataStr = power
.filter(new NoneFilter());
DataStream<Tuple2<Integer,String>> modDataStrForLR = modDataStr.flatMap(new powerFlatMap())
.keyBy(0);
modDataStrForLR .writeAsText("./powerFlatMapForLR");
DataStream<String> powerFlatMapForKmeansMLib = modDataStr.flatMap(new powerFlatMapForKmeansMLib());
powerFlatMapForKmeansMLib.print();
powerFlatMapForKmeansMLib.writeAsText("./powerFlatMapForKmeansMLib");
// run the prediction pipeline
env.execute("household_power Analise");
}
生成的用于做线性回归的数据特征文件部分内容如下:
0,0,0,1,0,0,1,0,0,5.374,0.498,0.0,0.0,2.0,17.0,
0,0,0,1,0,0,1,0,0,4.448,0.498,0.0,0.0,1.0,17.0,
0,0,0,1,0,0,1,0,0,3.266,0.0,0.0,0.0,0.0,18.0,
0,0,0,1,0,0,1,0,0,3.236,0.0,0.0,0.0,0.0,17.0,
0,0,0,1,0,0,1,0,0,4.058,0.2,0.0,0.0,0.0,17.0,
Spark离线模型—根据电量预测季节
根据用电情况预测是否是冬季(有点傻…)
object SparkRF {
case class Power(
month: Double,
Spring: Double, summer: Double, autumn: Double, winter: Double, morning: Double, noon: Double, afternoon: Double, evening: Double, beforeDawn: Double, Global_active_power: Double,
Global_reactive_power: Double, Voltage: Double, Global_intensity: Double, Sub_metering_1: Double, Sub_metering_2: Double, Sub_metering_3: Double
)
def parsePower(line: Array[Double]): Power = {
Power(
line(0),
line(1), line(2), line(3), line(4), line(5),
line(6) , line(7) , line(8), line(9) , line(10) ,
line(11), line(12) , line(13), line(14) , line(15) ,
line(16)
)
}
def parseRDD(rdd: RDD[String]): RDD[Array[Double]] = {
rdd.map(_.split(",")).map(_.map(_.toDouble))
}
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("SparkDFebay").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val path="D:/code/flink/PowerModData/4"
import sqlContext.implicits._
val powerRdd = parseRDD(sc.textFile(path)).map(parsePower)
val powerDF=powerRdd.toDF().cache()
powerDF.registerTempTable("PowerKmeans")
val Cols = Array("Spring", "summer", "autumn", "winter", "morning",
"noon", "afternoon", "evening", "beforeDawn", "Global_active_power",
"Global_reactive_power", "Voltage", "Global_intensity", "Sub_metering_1", "Sub_metering_2",
"Sub_metering_3")
val featureCols = Array("Global_active_power","Global_reactive_power", "Global_intensity","Sub_metering_2", "Sub_metering_3")
val feature1Cols = Array("Global_active_power","Spring", "summer", "autumn", "winter", "morning", "noon", "afternoon", "evening", "beforeDawn")
val assembler = new VectorAssembler().setInputCols(featureCols).setOutputCol("features")
val df2 = assembler.transform(powerDF)
df2.show(8)
val labelIndexer = new StringIndexer().setInputCol("winter").setOutputCol("label")
val df3 = labelIndexer.fit(df2).transform(df2)
df3.show
val splitSeed = 5043
val Array(trainingData, testData) = df3.randomSplit(Array(0.7, 0.3), splitSeed)
val classifier = new RandomForestClassifier().setImpurity("gini").setMaxDepth(3).setNumTrees(20).setFeatureSubsetStrategy("auto").setSeed(5043)
val model = classifier.fit(trainingData)
val predictions = model.transform(testData)
model.toDebugString
predictions.show
val evaluator = new BinaryClassificationEvaluator().setLabelCol("label")
val accuracy = evaluator.evaluate(predictions)
println("accuracy fitting:" + accuracy)
}
}
运行结果:
accuracy fitting:0.6778437355975941
Spark 离线定时任务做Kmeans聚类:
flink 处理的Kmeans 格式数据集:
12,3.894,0.234,0.0
12,3.994,0.408,0.0
12,3.422,0.06,18.0
12,6.936,0.082,18.0
12,4.552,0.196,17.0
Spark定时离线训练任务:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkDFebay").setMaster("local")
val sc = new SparkContext(conf)
val file="D:/code/flink-training-exercises-master/powerFlatMapForKmeansMLib/8"
val rawTrainingData = sc.textFile(file)
val RDDData = rawTrainingData.map(line => {
Vectors.dense(line.split(",").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
}).cache()
val Array(trainingData, testData) = RDDData.randomSplit(Array(0.7, 0.3))
//选取最合适的分类数
val ks: Array[Int] = Array(3, 4, 5, 6, 7, 8, 9, 10, 11, 12)
var ret:Map[Int,Double] =Map()
ks.foreach(cluster => {
val model: KMeansModel = KMeans.train(trainingData, cluster, 30, 1)
val ssd = model.computeCost(trainingData)
ret += (cluster->ssd)
})
ret.foreach{ i =>
println( "Key = " + i )}
}
K为12时的误差相对最小:
Key = (5,512.0118262388754)
Key = (10,216.71946399437297)
Key = (6,437.06659783173933)
Key = (9,244.55911004099448)
Key = (12,152.3216833039682)
Key = (7,384.5780125426356)
Key = (3,1088.713054854713)
Key = (11,175.84191616805106)
Key = (8,307.5536910695736)
Key = (4,633.9407541008707)k=12 -> 53.965646951056
Spark Stream实现准实时模型训练–线性回归
- 使用sparkstreaming ML的线性回归函数
val path="D:/code/flink/PowerModData"//被监控的实时流文件目录,由前面的flink服务实时生成并更新文件
val trainingData = ssc.textFileStream(path).map(LabeledPoint.parse).cache()
val testData = ssc.textFileStream(path).map(LabeledPoint.parse)
val numFeatures = 8//特征的数量
val model = new StreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.zeros(numFeatures))
model.trainOn(trainingData)
val ret = model.predictOnValues(testData.map(lp => (lp.label, lp.features)))
ret.print()

没有评论