整个机器学习的流程主要分如下几个主要过程:
- 业务理解
- 数据分析理解
- 数据预处理
- 建模
- 模型效果评估
- 使用合格的模型做预测
数据分析理解是机器学习建模的基础,目的是分析挖掘数据维度中和预测目标强相关的因素, 剔除不相关或者弱相关的因素, 用于后续的机器学习;
Python ,spark框架中常用dataframe结构处理数据集,下面使用python+银行营销数据做数据分析实践:
1 理解分析数据
1.1 加载数据并理解数据有哪些维度信息:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("D:/code/dataML/ibank-additional.csv",sep =";")
print(df.head())打印结果,可以看出维度信息,哪些是数值型,哪些是字符串型
age job marital ... euribor3m nr.employed y
0 30 blue-collar married ... 1.313 5099.1 no
1 39 services single ... 4.855 5191.0 no
2 25 services married ... 4.962 5228.1 no
3 38 services married ... 4.959 5228.1 no
4 47 admin. married ... 4.191 5195.8 no1.2 理解数据集中 数值型 数据的分布统计情况:
print(df.describe())
打印结果:
- 总数据量有4119个
- 数据中客户大部分年龄均方差在40岁,最小18岁,最大88岁,50%的客户年龄>38岁,75%客户年龄>47岁
- …
age duration ... euribor3m nr.employed
count 4119.000000 4119.000000 ... 4119.000000 4119.000000
mean 40.113620 256.788055 ... 3.621356 5166.481695
std 10.313362 254.703736 ... 1.733591 73.667904
min 18.000000 0.000000 ... 0.635000 4963.600000
25% 32.000000 103.000000 ... 1.334000 5099.100000
50% 38.000000 181.000000 ... 4.857000 5191.000000
75% 47.000000 317.000000 ... 4.961000 5228.100000
max 88.000000 3643.000000 ... 5.045000 5228.100000
1.3 分析各个维度信息和 标签列Y的相关性
age 和 y的相关性分析:
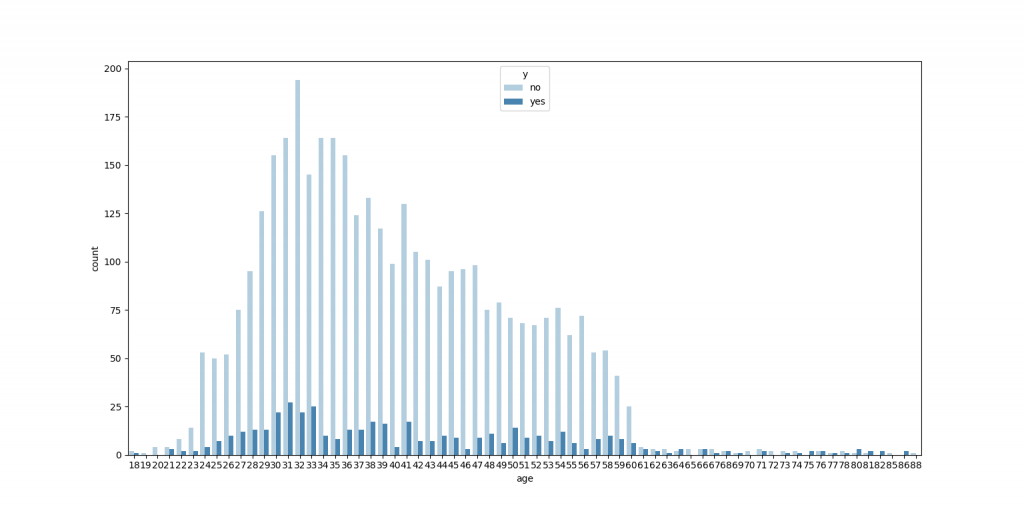
sns.countplot(x = "age", hue ="y",data = df, palette = "Blues")
plt.show( )年龄和Y有一定相关性…年龄到60岁后买理财产品的比例相对较大,但绝对人数较少,32岁左右买理财产品的比例相对较低
marital和 y的相关性分析:
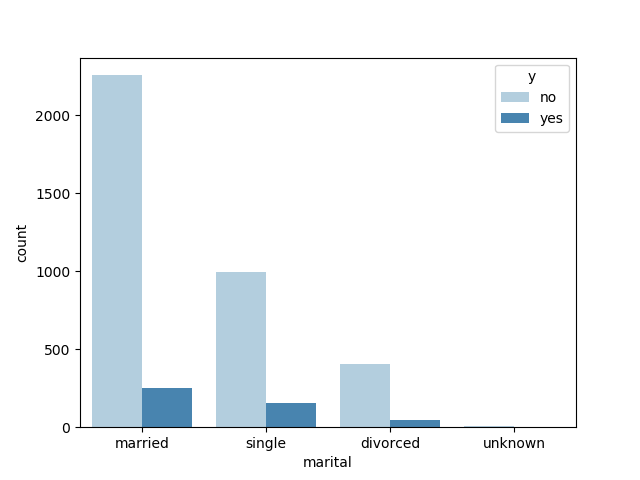
sns.countplot(x = "marital", hue ="y",data = df, palette = "Blues")
plt.show( )显示已婚的人群中,买理财产品的比例相对比较低,但购买的总人数较多
学历和y值的关系:
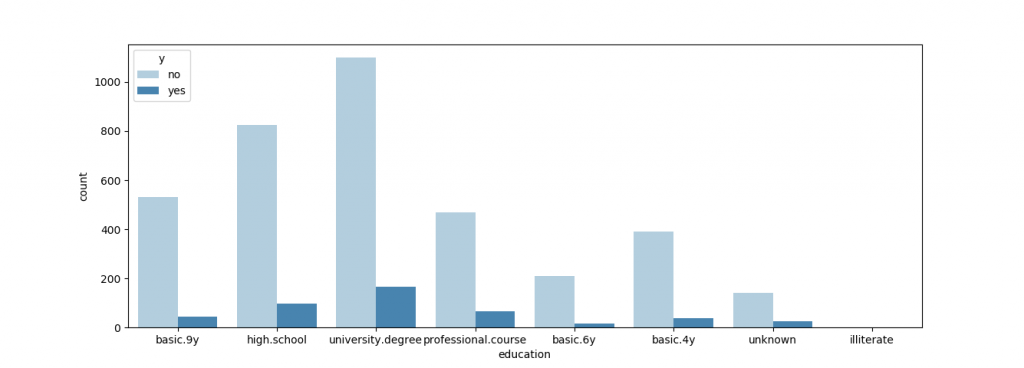
sns.countplot(x = "education", hue ="y",data = df, palette = "Blues")
plt.show( )专家级别的客户总人数不算最多,但是购买比例较高
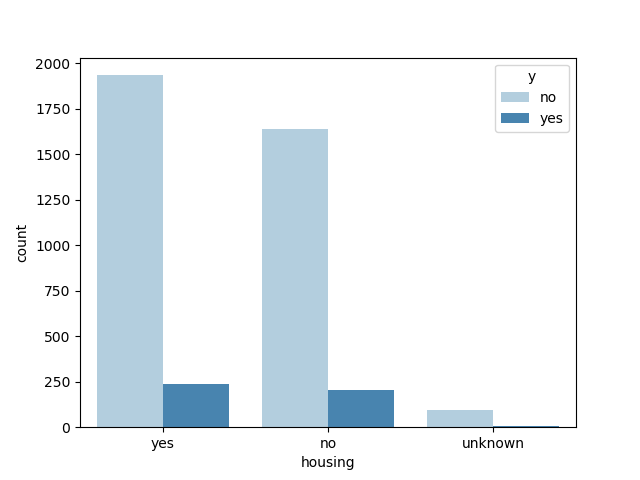
是否有房贷和y值的关系:(似乎差异不大,弱因子,可以考虑剔除)
是否有个人贷款和y值的关系:
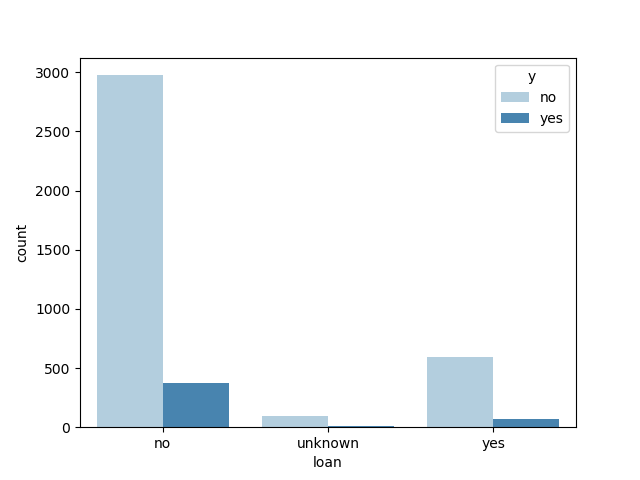
上次联系通信方式和y的关系:
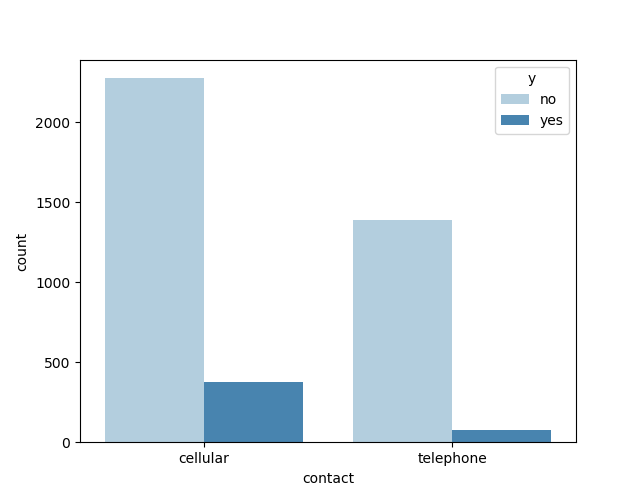
month(上次联系的月份)与y的关系:
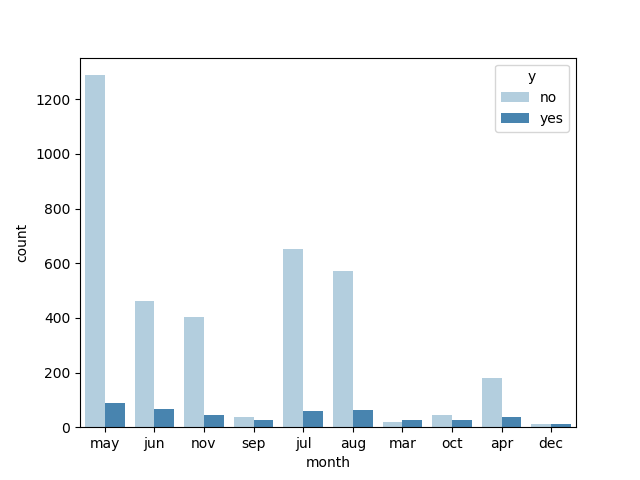
day_of_week(上次联系的星期几)与y 的关系:(差异不大,弱因子,可以考虑剔除)
其他维度数据与y相关性分析类似,不赘述
1.4 分析数值型数据维度之间的相关性:
print(df.corr())
打印结果:
age duration ... euribor3m nr.employed
age 1.000000 0.041299 ... -0.015033 -0.041936
duration 0.041299 1.000000 ... -0.032329 -0.044218
campaign -0.014169 -0.085348 ... 0.159435 0.161037
pdays -0.043425 -0.046998 ... 0.301478 0.381983
previous 0.050931 0.025724 ... -0.458851 -0.514853
emp.var.rate -0.019192 -0.028848 ... 0.970308 0.897173
cons.price.idx -0.000482 0.016672 ... 0.657159 0.472560
cons.conf.idx 0.098135 -0.034745 ... 0.276595 0.107054
euribor3m -0.015033 -0.032329 ... 1.000000 0.942589
nr.employed -0.041936 -0.044218 ... 0.942589 1.000000
可视化展现:
f,ax = plt.subplots(figsize=(10, 10))
sns.heatmap(df.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax)
plt.show()矩阵内容斜对称,数值越大表示越正相关,否则负相关
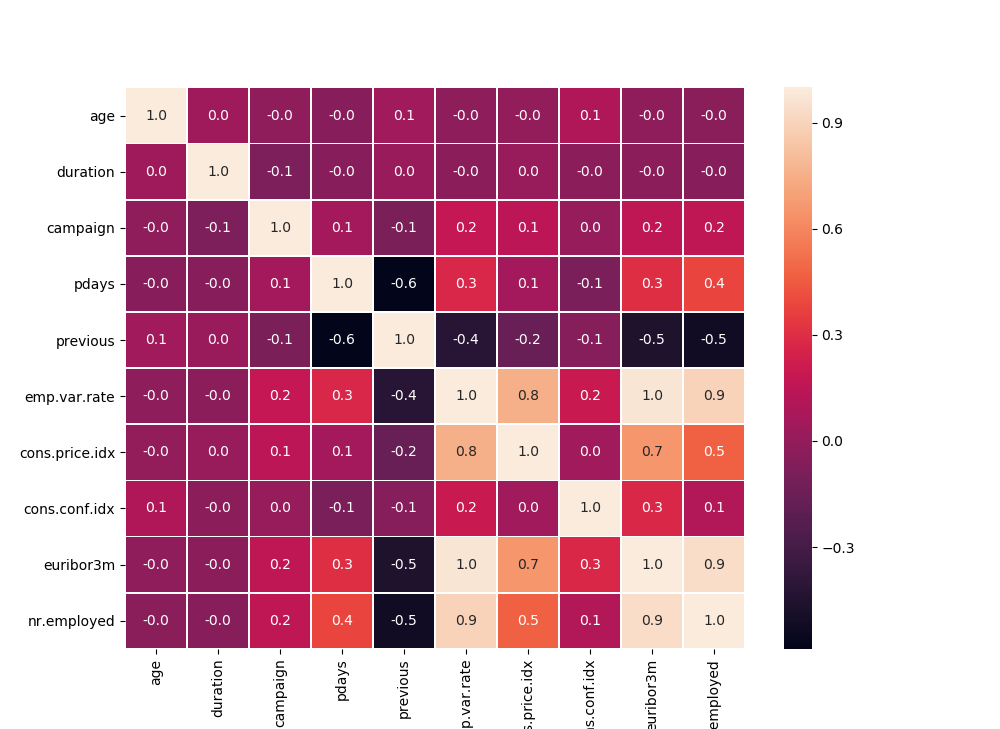
从上图结果很直观的发现几个相关性较大的维度:
euribor3m(3个月的利率) 和emp.var.rate(就业率)
nr.employed(就业人数)和emp.var.rate
nr.employed和euribor3m
相关性特别强的因子之间, 我们也许只要选择其中的一个即可,可以减少机器学习算法的数据特征数量;
由于标签列Y目前不是数值类型所以,无法直接使用heatmap发现其他列与它的相关性, 可以先把Y和其他列数据先数值化后再生成热力图再观察一下:)
1.5 分析 非数值型数据的分布情况:
print(df.describe(include=['O']))打印结果
a. 一共有4119条数据
b. Job 没有空值,且它有12种类型,其中最多的类型是admin 有1012个约25%
c. marital 也没有空值,它有4种类型,其中最多的是married类型,有2509个约60%
d. education也没有空值,它有8种类型,其中类型最多的是university.degree,有1264个约31%
…
job marital education ... day_of_week poutcome y
count 4119 4119 4119 ... 4119 4119 4119
unique 12 4 8 ... 5 3 2
top admin. married university.degree ... thu nonexistent no
freq 1012 2509 1264 ... 860 3523 3668
[4 rows x 11 columns]
2 数据预处理
主要包括空值处理, 极端值剔除,数值化,标准化等操作
按照不同类型的数据分成3类: 数值型, 2元分类型, 多元分类型 (方便后续分别做数值化处理)
numeric_attrs = ['age', 'duration', 'campaign', 'pdays', 'previous',
'emp.var.rate', 'cons.price.idx', 'cons.conf.idx',
'euribor3m', 'nr.employed' ]
bin_attrs = ['default', 'housing', 'loan']
cate_attrs = ['poutcome', 'education', 'job', 'marital',
'contact', 'month', 'day_of_week']
2.1 极端值剔除:
在数据可视化分析时, 已经能发现一些极端值, 比如age中的年龄<20,>80岁的场景, 可以考虑剔除;
2.2 数值化&标准化处理
多元分类类型数值化处理函数:
def encode_cate_attrs(data, cate_attrs):
data = encode_edu_attrs(data)#education是有序分类变量编码,单独处理
cate_attrs.remove('education')
#无序分类变量编码
for i in cate_attrs:
dummies_df = pd.get_dummies(data[i])#get_dummies 是利用pandas实现one hot encode的方式
dummies_df = dummies_df.rename(columns=lambda x: i + '_' + str(x))
data = pd.concat([data, dummies_df], axis=1)
data = data.drop(i, axis=1)
return data
#education是有序分类变量编码
def encode_edu_attrs(data):
values = ["illiterate", "basic.4y", "basic.6y", "basic.9y",
"high.school", "professional.course", "university.degree"]
levels = range(1, len(values) + 1)
dict_levels = dict(zip(values, levels))
for v in values:
data.loc[data['education'] == v, 'education'] = dict_levels[v]
return data二元分类数值化处理函数:
def encode_bin_attrs(data, bin_attrs):
for i in bin_attrs:
data.loc[data[i] == 'no', i] = 0
data.loc[data[i] == 'yes', i] = 1
return data数值型数据向量化&标准化处理函数:
pandas.qcut()函数来离散化连续数据(Spark中提供bucketize实现),它使用分位数对数据进行划分(分箱: bining),可以得到大小基本相等的箱子(bin),以区间形式表示。然后使用pandas.factorize()函数将区间转为数值
比如,age 我们并不需要所有的离散值分析, 只需要分几个年龄阶段就可以了
def trans_num_attrs(data, numeric_attrs):
bining_num = 10
bining_attr = 'age'
data[bining_attr] = pd.qcut(data[bining_attr], bining_num)
data[bining_attr] = pd.factorize(data[bining_attr])[0] + 1
for i in numeric_attrs:
scaler = preprocessing.StandardScaler()
data[i] = scaler.fit_transform(data[i].values.reshape(-1,1))
return data
先把所有分类数据数值化,再把所有数值化后的数据通过trans_num_attrs 向量化和标准化处理:
data = encode_cate_attrs(data, cate_attrs)
data = encode_bin_attrs(data, bin_attrs)
data = trans_num_attrs(data, numeric_attrs)
data['y'] = data['y'].map({'no': 0, 'yes': 1}).astype(int)2.3 空数据处理:
空值处理一般有3种方式:
a. 赋值默认值
b. 删除空值多的维度
c. 使用已有值预测出空值
data['age'] = data.age.fillna(data.age.mean())
一般一个维度的数据缺失率>=15% 就会放弃使用这个维度的数据,以免数据失真
数值类型的数据判断:
total = df.isnull().sum() percent = (df.isnull().sum()/df.isnull().count()) missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) print(missing_data)
打印结果如下,显示各维度都无空数据
Total Percent age 0 0.0 campaign 0 0.0 cons.conf.idx 0 0.0 cons.price.idx 0 0.0 contact 0 0.0 day_of_week 0 0.0 default 0 0.0 duration 0 0.0 education 0 0.0 emp.var.rate 0 0.0 euribor3m 0 0.0 housing 0 0.0 job 0 0.0 loan 0 0.0 marital 0 0.0 month 0 0.0 nr.employed 0 0.0 pdays 0 0.0 poutcome 0 0.0 previous 0 0.0 y 0 0.0
删除缺失数据较多的列
#dealing with missing data
df= df.drop((missing_data[missing_data['Percent'] > 0.15]).index,1)
df.isnull().sum().max() #最后确认没有missing数据非数值类维度是否有空值,比如”unknown”:
for i in df.columns:
if type(df[i][0]) is str:
print("unknown value count in "+i+":\t"+str(df[df[i]=="unknown"]['y'].count()))打印结果,发现defalut维度缺失的量比较大, 803/4119=0.195 , 已经>15%可以考虑剔除该维度数据:
unknown value count in job: 39
unknown value count in marital: 11
unknown value count in education: 167
unknown value count in default: 803
unknown value count in housing: 105
unknown value count in loan: 105
unknown value count in contact: 0
unknown value count in month: 0
unknown value count in day_of_week: 0
unknown value count in poutcome: 0
unknown value count in y: 0如果缺失数据较多的维度比较重要删除也不太适合, 也有人使用数据完整的行作为训练集,以此来预测缺失值,变量housing,loan,education和default的缺失值可以采取此法,
由于模型只能处理数值变量,需要先将分类变量数值化,然后进行预测,比如使用随机森林预测缺失值:
def fill_unknown(data, bin_attrs, cate_attrs, numeric_attrs):
fill_attrs = []
for i in bin_attrs + cate_attrs:
if data[data[i] == 'unknown']['y'].count() < 500:
# delete col containing unknown
data = data[data[i] != 'unknown']
else:
fill_attrs.append(i)
data = encode_cate_attrs(data, cate_attrs)
data = encode_bin_attrs(data, bin_attrs)
data = trans_num_attrs(data, numeric_attrs)
data['y'] = data['y'].map({'no': 0, 'yes': 1}).astype(int)
for i in fill_attrs:
test_data = data[data[i] == 'unknown']
testX = test_data.drop(fill_attrs, axis=1)
train_data = data[data[i] != 'unknown']
trainY = train_data[i]
trainX = train_data.drop(fill_attrs, axis=1)
test_data[i] = train_predict_unknown(trainX, trainY.astype('int'), testX)
data = pd.concat([train_data, test_data])
return data
def train_predict_unknown(trainX, trainY, testX):
forest = RandomForestClassifier(n_estimators=100)
forest = forest.fit(trainX, trainY)
test_predictY = forest.predict(testX).astype(int)
return pd.DataFrame(test_predictY, index=testX.index)
data = fill_unknown(data, bin_attrs, cate_attrs, numeric_attrs)预处理后的部分数据样例:
age,education,default,housing,loan,duration,campaign,pdays,previous,emp.var.rate,cons.price.idx,cons.conf.idx,euribor3m,nr.employed,y,poutcome_failure,poutcome_nonexistent,poutcome_success,job_admin.,job_blue-collar,job_entrepreneur,job_housemaid,job_management,job_retired,job_self-employed,job_services,job_student,job_technician,job_unemployed,marital_divorced,marital_married,marital_single,contact_cellular,contact_telephone,month_apr,month_aug,month_dec,month_jul,month_jun,month_mar,month_may,month_nov,month_oct,month_sep,day_of_week_fri,day_of_week_mon,day_of_week_thu,day_of_week_tue,day_of_week_wed
29528,-1.5407029621226411,5,0,1,0,-0.9616741473849848,0.8792728510796384,0.19471978718933916,-0.349340630297601,-1.1976943722378013,-0.8638900037329893,-1.4230792758363522,-1.2768324248035627,-0.9402874889310989,0,0,1,0,0,1,0,0,0,0,0,0,0,0,0,0,1,0,1,0,1,0,0,0,0,0,0,0,0,0,0,1,0,0,0
11077,-0.8373901096042032,5,0,0,0,-0.3946898019668333,0.15674760650699962,0.19471978718933916,-0.349340630297601,0.8403751233526144,1.5386637396382556,-0.27756645910974154,0.7740270002200575,0.8456503392074235,0,0,1,0,0,0,0,0,0,0,0,0,0,1,0,0,1,0,0,1,0,0,0,0,1,0,0,0,0,0,0,0,0,0,1
4680,-0.4857336833449843,4,0,0,0,-0.5682564383193286,0.8792728510796384,0.19471978718933916,-0.349340630297601,0.6493061081410131,0.7245609963807991,0.8895598069890682,0.7140637221198453,0.33202015762649456,0,0,1,0,0,1,0,0,0,0,0,0,0,0,0,0,1,0,0,1,0,0,0,0,0,0,1,0,0,0,0,0,0,0,1
之后可以保存数据用于机器学习了,此处不再赘述
没有评论