BlockManager是一个嵌入在 spark 中的 key-value型分布式存储系统,也是 Master-Slave 结构的, RDD-Cache、 Shuffle-output、broadcast 等的实现都是基于BlockManager来实现的:
- spark shuffle 的过程总用到了 BlockManager 作为数据的中转站
- spark broadcast 调度 task 到多个 executor 的时候, broadCast 底层使用的数据存储层
- spark streaming 一个 ReceiverInputDStream 接受到的数据也是先放在 BlockManager 中, 然后封装为一个 BlockRdd 进行下一步运算的
- 如果我们 对一个 rdd 进行了cache, cacheManager 也是把数据放在了 blockmanager 中, 截断了计算链依赖, 后续task 运行的时候可以直接从 cacheManager 中获取到 cacherdd ,不用再从头计算。
-
BlockManager 原理图
BlockManager 在一个 spark 应用中作为一个本地缓存运行在所有的节点上, 包括所有 driver 和 executor上, 基于用户Application所关联的一个Driver和多个Executor构建了一个Block管理集群:Driver上的(BlockManagerMaster, BlockManagerMasterEndpoint)是集群的Master角色,所有Executor上的(BlockManagerMaster, RpcEndpointRef)作为集群的Slave角色; 在 driver 上面的 BlockManager (Master)(在 Application 启动的时候会在 spark-env.sh 中注册)是负责管理整个集群所有 Executor 中的 BlockManager;
BlockManager(Master)拥有BlockManagerMasterEndpoint的actor和所有BlockManagerSlaveEndpoint的ref, 可以通过这些引用对executor( slave) 下达命令。
executor 节点上的BlockManagerMaster 则拥有BlockManagerMasterEndpoint的ref和自身BlockManagerSlaveEndpoint的actor。可以通过 Master的引用注册自己。
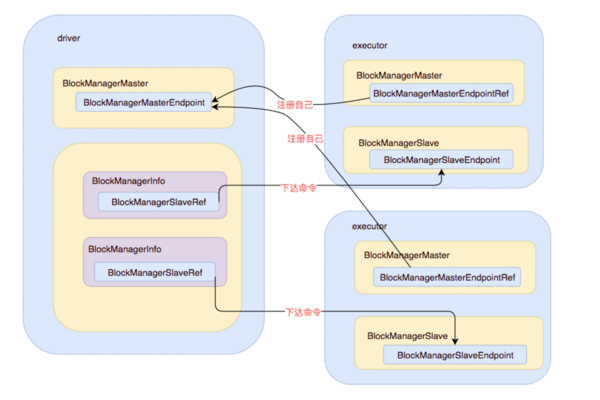
在master(driver) 和 slave(executor) 可以正常的通信之后, 就可以根据设计的交互协议进行交互, 整个分布式缓存系统也就运转起来了。
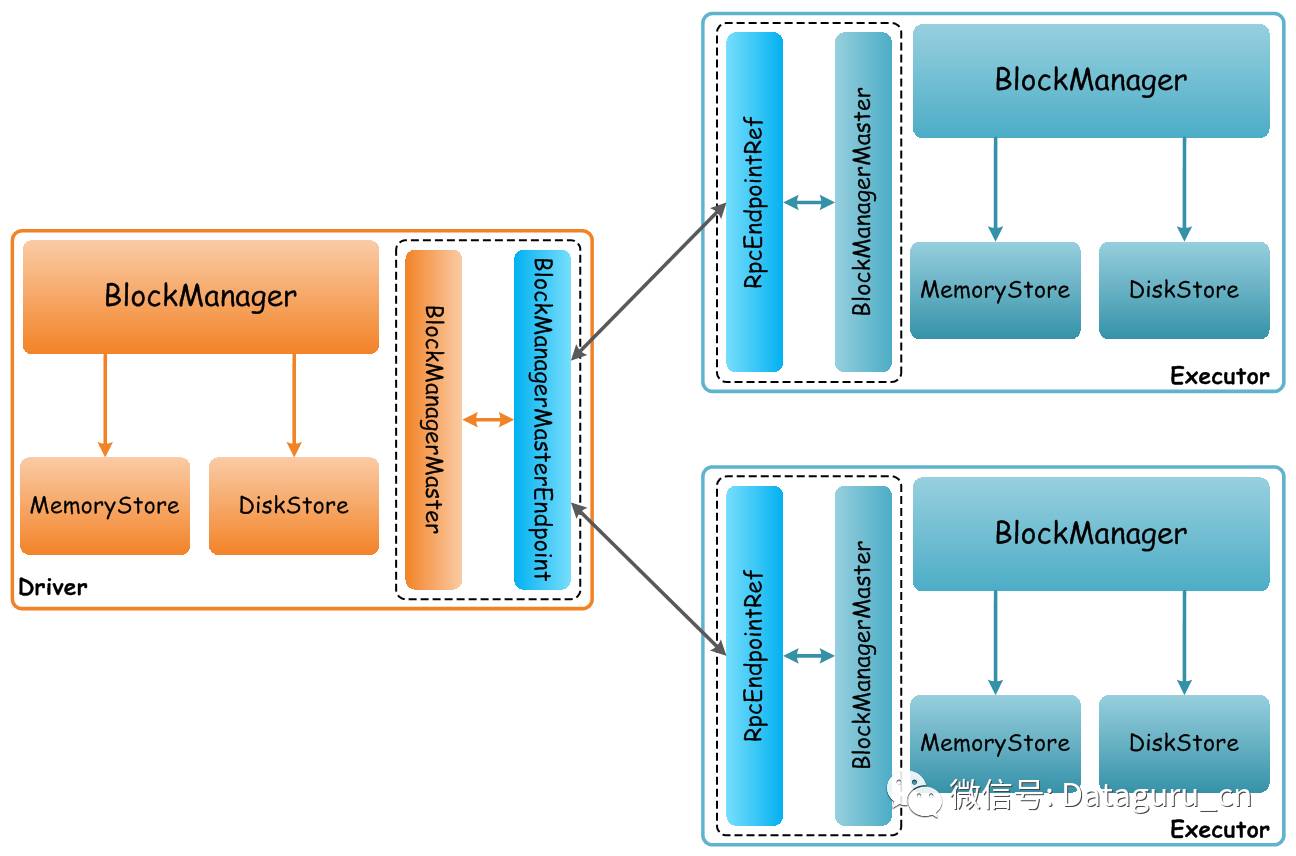
每个Executor上都有一个BlockManager实例,负责管理用户提交的该Application计算过程中获取RDD数据,有几种场景:
当前Executor上存储在RDD对应Partition的经过处理后需要获取的Block数据
- 本地获取:根据StorageLevel设置,如果是存储在内存中,则从本地的MemoryStore中查询,存在则读取并返回;如果是存储在磁盘上,则从本地的DiskStore中查询,存在则读取并返回
- 远程获取: 如果数据本地不存在,但是其他Executor上已经处理过并缓存了Block数据,则会从远程的Executor读取, 就会引发ChunkFetch类消息的网络通信(之前文章有介绍)
BlockManager 对本地和远程提供一致的 get 和put 数据块接口,BlockManager 本身使用不同的存储方式来存储这些数据, 包括 memory, disk, off-heap
远程获取block数据的时序图:
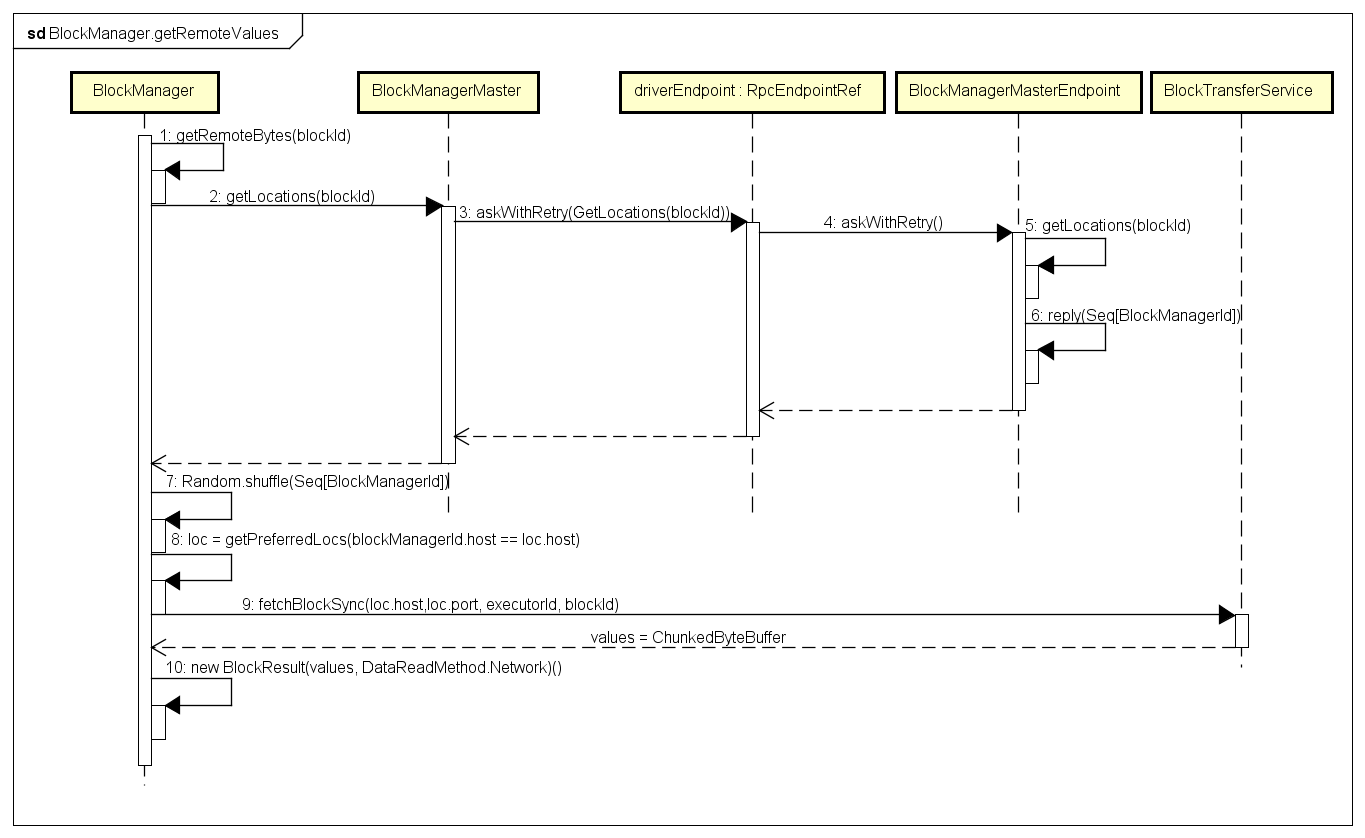
-
Spark中的partition和block的关系
在计算框架层面上 RDD是由不同的partition组成的,我们所进行的transformation和action是在partition上面进行的;而在storage模块内部,RDD又被视为由不同的block组成,对于RDD的存取是以block为单位进行的,本质上partition和block(可以理解为装partition的小盒子)是等价的
抽象上我们的操作是在partition层面上进行的,但是partition最终还是被映射成为block, 因此实际上我们的所有操作都是对block的处理和存取;
block位于存储空间、partition 位于计算空间
block的大小是固定的、partition 大小是不固定的
block是有冗余的、不会轻易丢失,partition(RDD)没有冗余设计、丢失之后重新计算得到
那么partition是如何与block对应上的呢?
RDD计算的核心函数是iterator()函数, 如果当前RDD的storage level不是NONE的话,表示该RDD在BlockManager中有存储,那么调用相关函数计算RDD,在这个函数中partition和block发生了联系:
首先根据RDD id和partition index构造出block id (rdd_xx_xx),接着从BlockManager中取出相应的block。
- 如果该block存在,表示此RDD在之前已经被计算过和存储在BlockManager中,因此取出即可,无需再重新计算。
- 如果该block不存在则需要调用RDD的computeOrReadCheckpoint()函数计算出新的block,并将其存储到BlockManager中。
需要注意的是block的计算和存储是阻塞的(PUT写入操作 操作之前会加锁来避免多线程的问题),若另一线程也需要用到此block则需等到该线程block的loading结束。
-
Spark 存储相关的性能参数
spark.memory.fraction
- 参数说明:堆内存中用于执行、混洗和存储(缓存)的比例。这个值越低,则执行中溢出到磁盘越频繁,同时缓存被逐出内存也更频繁。这个配置的目的,是为了留出用户自定义数据结构、内部元数据使用的内存。推荐使用默认值。请参考this description.
spark.memory.storageFraction
- 参数说明:不会被逐出内存的总量,表示一个相对于 spark.memory.fraction的比例。这个越高,那么执行混洗等操作用的内存就越少,从而溢出磁盘就越频繁。推荐使用默认值。
spark.storage.memoryMapThreshold
- 参数说明:该参数用于表示spark从磁盘上读文件时,最小单位不能少于该设定值,默认2m,小于或者接近操作系统的每个page的大小;
- 参数调优建议:通常,内存映射块是有开销的,应该比接近或小于操作系统的页大小
没有评论