spark中网络通信无处不在,如下图standalone模式下和核心组件通信流程
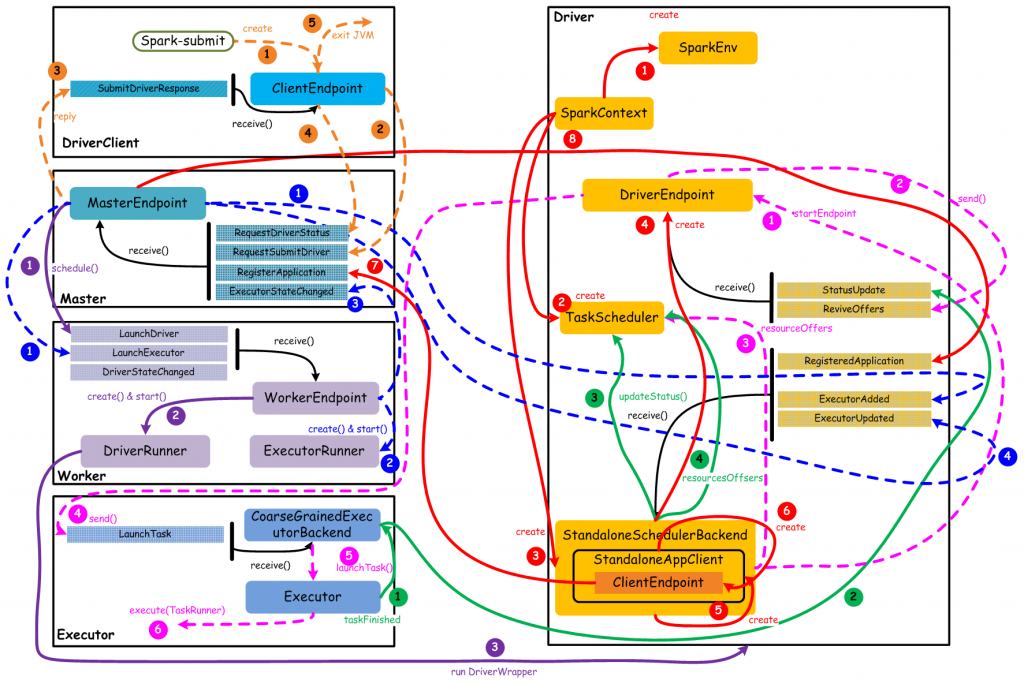
例如:
- driver和master的通信,比如driver会向master发送RegisterApplication消息
- master和worker的通信,比如worker会向master上报worker上运行Executor信息
- executor和driver的的通信,executor运行在worker上,spark的tasks被分发到运行在各个executor中,executor需要通过向driver发送任务运行结果。
- worker和worker的通信,task运行期间需要从其他地方fetch数据,这些数据是由运行在其他worker上的executor上的task产生,因此需要到worker上fetch数据(上图中无该通信流程)
1. Spark中三种类型的消息:
- RPC消息:用于抽象所有spark中涉及到RPC操作时需要传输的消息,通常这类消息很小,一般都是些控制类消息(相对于chunkFetch类消息)
- ChunkFetch消息: 用于抽象所有spark中涉及到数据拉取操作时需要传输的消息,它用于shuffle数据以及RDD Block数据传输,例如:
在shuffle阶段,reduce task会去拉取map task结果中的对应partition数据,这需要发起一个ChunkFetch;
当RDD被缓存后,如果节点上没有所需的RDD Block,则会发起一个ChunkFetch拉取其他节点上的RDD Block
- Stream消息:主要用于driver到executor传输jar、file文件等
2.RPC消息处理:
基于netty网络框架,Spark rpc创建NettyRpcEnv时通过TransportContext创建netty的server端和client
2.1 业务流程:
客户端:
- 发送一个RPC请求消息(RpcRequest或OneWayMessage),经过编码到网络;
- 发送RpcRequest的时候,会注册一个RpcResponseCallback,通过requestId来标识,这样在收到响应消息的时候,根据响应消息中的requestId就可以取出对应的RpcResponseCallback对响应消息进行处理
服务端:
- 网络消息接收,解码到TransportChannelHandler–》TransportRequestHandler–》RpcHandler,RpcHandler专门用来处理RPC请求消息,RpcHandler中有两个关键receive接口,带callback(处理RpcRequest)和不带callback(处理OneWayMessage);
- 当收到RpcRequest时,处理后会在callback中发送响应消息,成功则发送RpcResponse,失败则发送RpcFailure。
- 当收到OneWayMessage时,处理后则直接不用管,客户端也不用关心是否被处理了
2.2 RPC实现框架示意图:
spark 中RPC通信都需要创建rpcEnv,实际上是实例NettyRpcEnv;
rpc两端称为endpoint,服务端一端需要实现RpcEndpoint接口,如下图
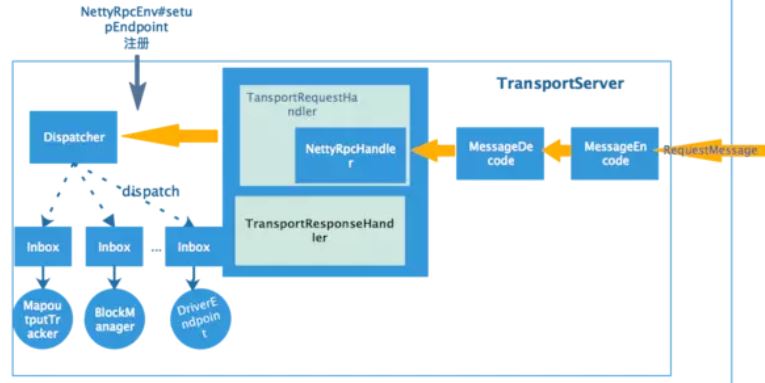
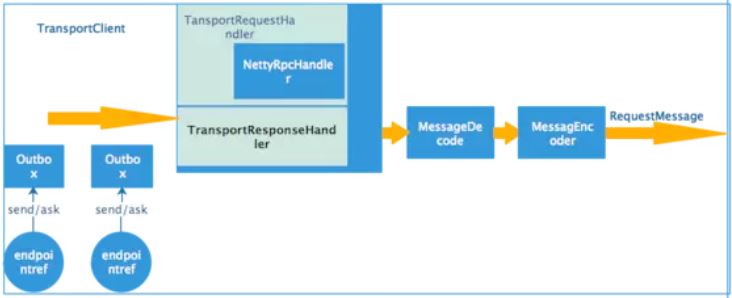
客户端一方需要注册的只是EndpointRef,通过EndpointRef发起服务请求。
3. ChunkFetch消息处理:
3.1 业务流程:
- 客户端(executor1)一般需要首先发送一个RPC请求,告诉服务端(executor2)需要拉取哪些数据;
- 服务端收到这个RPC请求后,会为客户端准备好需要的数据;
- 客户端收到RPC请求成功返回后(服务端表示数据准备好),客户端再发送ChunkFetchRequest消息;
- 服务端收到该消息后,拿到对应的数据,封装成ChunkFetchSuccess返回给客户端,如果出错或找不到对应的数据,则返回ChunkFetchFailure。
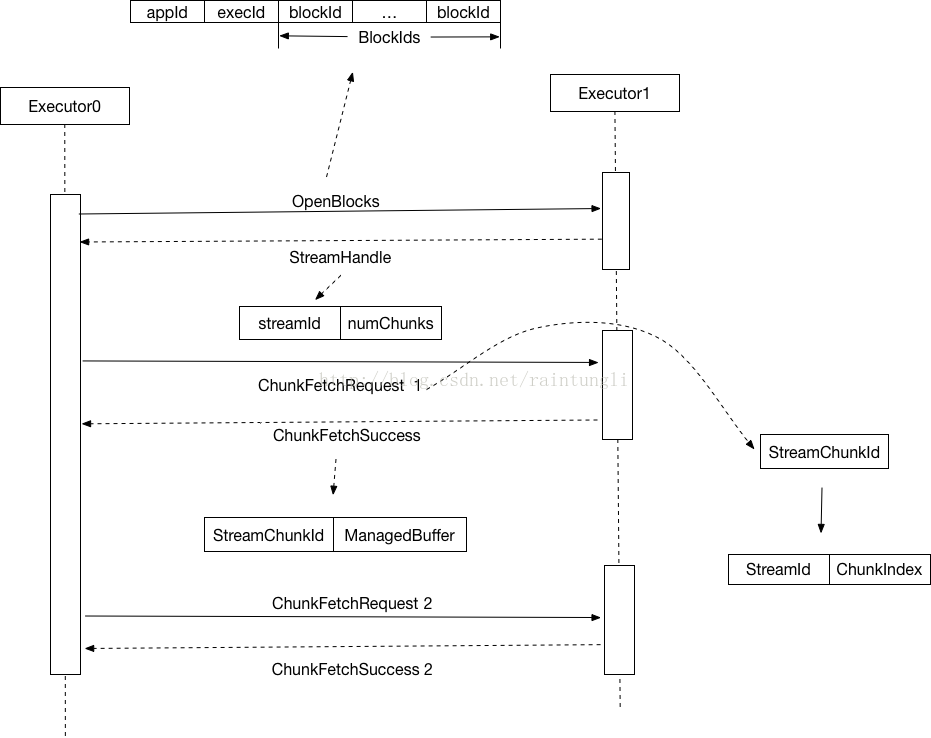
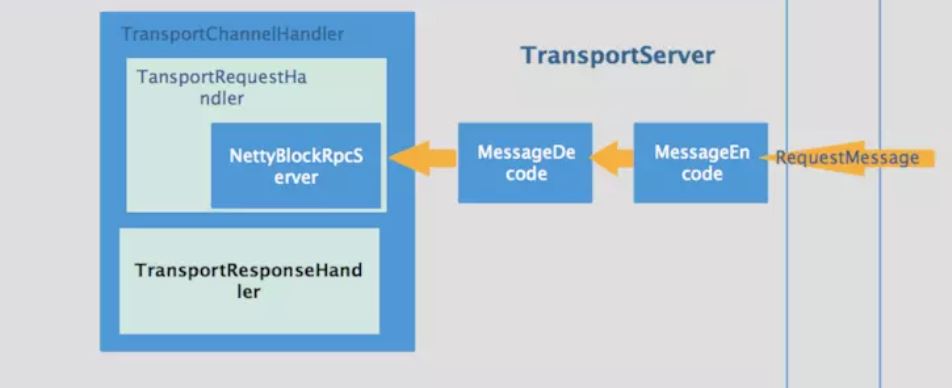
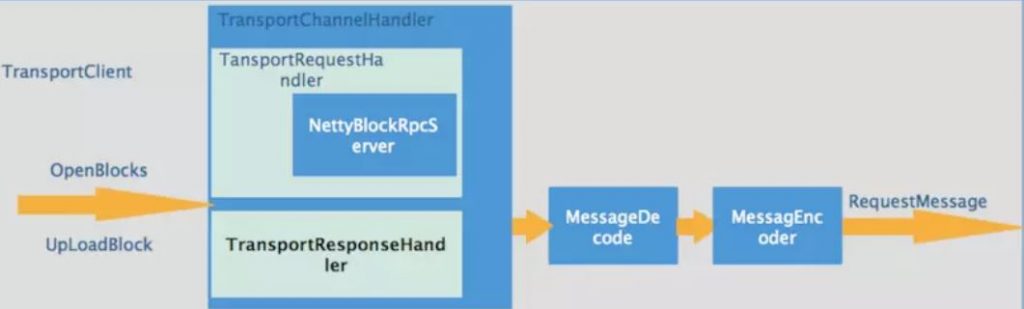
3.2 传输实现框架示意图:
NettyBlockTransferService是一个基于netty实现的数据传输服务,和NettyRpcEnv不同的是注册的handler由NettyRpcHandler变成了NettyBlockRpcServer
4.Stream消息处理:
也是基于netty 框架,主要用于文件服务。
- 客户端一般也需要首先发送一个RPC请求,告诉服务端需要打开一个stream,
- 服务端收到这个RPC请求后,会为客户端打开所需的文件流。
- 客户端RPC请求成功后(服务端表示数据准备好),客户端再发送StreamRequest消息
- 服务端收到该消息后,从准备好的StreamManager中打开对应的文件流,同时返回StreamResponse给客户端,如果出错或找不到对应的流,则返回XXXFailure。
5. 思考:
从上可以看出,用户编写的spark任务APP性能,受ChunkFetch类消息的通信次数和每次通信的数据量的影响会比较大;
比如shuffle类操作, 各个节点上的相同key都会先写入本地磁盘文件中,shuffle过程就是将分布在集群中多个节点上的同一个key,通过网络传输拉取到同一个节点上,进行聚合或join等操作, 这个过程中可能会发生大量的磁盘IO操作,以及数据的网络传输操作(ChunkFetch消息通信)。
因此除了磁盘IO, 网络数据传输也是shuffle性能较差的主要原因之一。
这也是为什么搭建建议 编写spark 任务程序时 能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子的原因。
没有评论